
Репликация средствами 1с распределенные базы данных как настроить
Обновлено: 04.07.2024
путь в букварях. мне просто так совестно бывает цитировать оттуда. Как будто я считаю собеседника ну. умственно отсталым.
Но если все-таки нужно, то вот:
Логшиппинг. одна база эктив, другая - стэндбай.. вторая - точная копия первой на какой-то момент, получена например из бэкапа все файлы журналов транзакций из одной базы отправляются в другую.(с ней само собой не работают, ведь в условии нет что с ней должны работать). И потом все что остается выполнить - команду роллфорвард для логов транзакции.. транзакции повторяются в стэндбай базе, мы заходим в нее конфигуратором - база обновлена.
(39)
в чем сложность ?
таблицы конфы не пресоздаются при реструктуризации, т.е. подойдет классическая репликация
в ДБ2 журнал - простой текстовый файл.. вернее набор.. который жмется. Но да. есть такой недостаток.
(41) изменили тип реквизита. как при репликации в базе приемнике все пройдет?
(44)
Вы путаете обновление конфигурации (конфы) и обновление БД
и сделать скрипты одновления.
нужно воспроизвести сам алгоритм обновления таблиц.
но это тема для отдельной ветки.
(45) я ниче не путаю. в (41) я конкретно спрашивал про варианты обновления конфигурации БД. то есть о метаданных. данные пока оставим в покое.
. обновление конфигурации (конфы) и обновление БД
это как понимать? обновление конфигурации термин понятный. а обновление БД это слишком абстрактно. что входит по вашему в это понятие?
view и пользователи тут вообще не причем.
(47)
для меня обновление конфигурации (то , что Вы назвали конфигурацией разработчика ) и обновление конфигурации бд разные понятия.
обновления конфигурации бд происходит в штатном монопольно и возможной реструктуризацией
обновление метаданных (в части описания структуры бд) конфигурации бд
без обновления структуры и данных в них (реструктуризации) не имет смысла.
тк возможна аварийная ситуация обращения к несуществующим или с измененым типом данных.
а варианты описаны в (45)
3 вариант вариант с дмл триггером нудобен, тк на триггеры можно возложить другие (сопутствующие задачи), хотя и вполне возможен.
о готовых продуктах не слышал тк сие нарушает лицензионность и сответственно рынок специфичен .
но очень вероятно у му-му есть подобный продукт.
тк я неоднократно сталкивался с их решениями не офишируемыми на сайте,
то ,возможно,и такой продукт есть, тк крупным заказчивам такой продукт очень пригодится,
чтобы не выгонять сотни пользователей или обновляться без обновленца.
(38) Спасибо. Эх если бы на русском. А мне не стыдно признаться в умственной отсталости в конкретной области. Но мозги же развиваются как мышцы.
Можешь дать конкретный советпо организации зеркала, репликации для базы только для чтения.
конце концов на начальном этапе можно после реструктуризации базы делать новый слепок базы.
Я не администратор и на такую задачу нанял бы толкового админа, но мне нужно самому знать все подводные камни и опыт других людей. На то форумы и нужны.
2(50) там конкретно написано.. буквально с рецептами. ну еще и читай (40)
вот чтобы мы ни сказали - она либо будет работать либо нет.. поэтому только провобовать
В твоем случе лучше обратить внимание на репликацию моментальных снимков. Но я вот точно уже не помню будет она работать для 1С или там засада где то. Делать надо.
Спасибо. Разгребусь и займусь. Самому интересно для многих решений когда нужно передавать только изменения.
Не понял до конца цели. Если балансировка нагрузки и резервное хранение - это действительно отдельная тема. Кстати в марте выступаем(я с коллегой) в Новосибе на научной конференции посвященной параллельным вычислениям. Там как раз тема будет о решении балансировки нагрузки для SQL серверов. Сейчас активно разрабатываем продукт с которым планируем на запад выходить. Казалось бы столько книг и теорий написано а реально работающих решений нет. То есть у нас и сейчас это реализовано но например есть в некоторых случаях задержка резервного сервера.(как раз на репликации сделано)Сейчас концептуально технологию поменяли. В том числе с применением аппаратных решений.
(58) Вообщем задавай конкретные технические вопросы на все отвечу. Скрывать нечего.
Какой тип репликации Одноранговая репликация или репликацию моментальных снимков использовать для моей схемы. Это даже не балансировка, а случай когда 1 из серверов по каким то причинам не может работать.
То есть 1 сервер основной где все изменяется, второй только для чтения.
Какие основные цели? Получить минимальную потерю данных или же балансировать нагрузку?
А вообще то из бесплатных решений посмотри в сторону логшипинга. Зеркалирование имеет ряд недостатков. Транзакционную репликацию нужно серьезно настраивать к тому же имеет ряд багов(поэтому от нее отказались). Моментальные снимки для твоего случая вообще не вариант.
(62) Самое хорошее решение - повышение аппаратной надежности (для первой части) и аппаратные же кластеры (для второй части). Все остальное в конечном итоге от лукавого, ибо рано или поздно вся эта красота приводит к геморрою.
В военных системах очень любят делать всяческие репликации для повышения отказоустойчивости и распределения нагрузки. Толку с них никакого. Раз в месяц-полтора возникает "клинч" и все встает колом.
(65) полуавтомаом, но в штатном режиме? почему не стали делать обновление конфы средствами скуля?
(66) имеется ввиду, обновление накатывается все таки платформой, или в обход нее?
(0) я может что-то не понял, но зачем репликация? Если надо в одну базу писать, а из другой читать - есть намного более простые и удобные варианты:
1. Лог-шиппинг. Настраивается просто, сразу умеет делать вторую ("резервную") базу доступной для чтения. Возможный косяк - после перехода на "резервный" сервер, придется на "основном" базу восстанавливать из бэкапа, обратный переход не предусмотрен.
Потеря данных, в случае аварии, может быть довольно большой - все бэкапы не доставленные на резервный сервер.
Даже SQL Server 2000 его умеет делать.
2. Зеркалирование. Настраивается тоже довольно просто. С одинэсными базами работает отлично (с восьмеркой, по крайней мере, за семерку не уверен).
Основная проблема в том, что нужен SQL Server Enterprise Edition, для того чтобы резервная база была доступна для чтения, поскольку это реализуется только через Snapshot (Standard этого не умеет).
Потеря данных, при аварии, либо незначительна, либо отсутствует. После сбоя, возможно, придется "первую" (ранее основную) базу восстанавливать из бэкапа, но это зависит от того как прошел "переход" на резервную базу.
Постановка задачи: имеется центральный офис и удаленный филиал (в разных городах). Между собой территории связаны медленным каналом. В центральном офисе хотят иметь актуальную копию информационной базы (ИБ) филиала.
Филиал использует конфигурацию 1С «Бухгалтерия предприятия» 8 (БП8) в файловом варианте.
Самый простой вариант - ежедневно копировать всю папку с ИБ по каналу из филиала в офис, делать это не позволяет делать медленный канал и большой объем ИБ.
Предлагается решение выполнять ежедневные репликации с помощью механизма Распределенной Информационной Базы (РИБ).
В терминах РИБ у нас имеется 2 узла главный (БП8 в филиале) и подчиненный (копия БП8 в центральном офисе).
1. Настройка главного узла
Вначале необходимо настроить главный узел. Для этого в ИБ филиала необходимо зарегистрироваться с административными правами. В основном меню программы выбрать пункт «Операции / Планы обмена. ». В планах обмена стандартной конфигурации БП8 уже созданы 4 стандартных плана обмена:
Текущий узел описан, теперь необходимо описать узел-приемник. Жмем <F9>, добавляем новый узел с именем «Копия БП» и кодом «Б02». Получаем два узла:
В РИБ может быть много подчиненных узлов и обмен будет производиться между одним главным узлом и каждым из подчиненных узлов, но для нашей «узкой» цели достаточно двух «Источник» (главный узел) и «Приемник» (подчиненный узел - копия БП).
Теперь физически создадим подчиненный узел (новую базу данных). Для этого необходимо встать на строчку узла «Копия БП» и нажать на значок «Создать начальный образ. » или выбрать это действие из меню:
Система предложит выбрать тип ИБ. Необходимо выбрать «На данном компьютере. ». Затем необходимо указать каталог, в котором будет создана новая ИБ. Лучше создать новую папку и там будет создана новая ИБ:
После этого в указанном каталоге будет создана новая ИБ 1С и в эту базу будут перенесены все данные из главной базы. Сразу стоит отметить, что новая ИБ не является точной копией исходной. В ней свои настройки (свой список пользователей и т.д.), переносятся только данные и модифицированные планы обмена, т.е. в новой ИБ останутся только два узла «Главный узел» и «Копия БП». Второй узел в новой ИБ будет предопределенным.
Если исходная ИБ большая и в ней работают пользователи, при создании начального образа возможны коллизии, поэтому операцию создания нового образа рекомендуется проводить на ИБ в монопольном режиме.
Если в главном узле было описано несколько подчиненных узлов, операцию по созданию начального образа ИБ необходимо провести для каждого узла, т.е. будет создано столько новых ИБ, сколько было описано узлов в исходной базе. Для наших целей достаточно одного подчиненного узла.
В момент создания начального образа, в главной базе будет создана таблица синхронизации объектов главной базы с этим узлом. В общем случае таких таблиц создается по количеству подчиненных узлов. При создании начального образа узла устанавливается признак синхронизации с узлом.
Теперь новую ИБ необходимо скопировать в центральный офис. После этого на обоих территориях будут одинаковые (в смысле данных) ИБ.
Созданную ИБ необходимо настроить как любую новую базу: ввести пользователей и т.д.
2. Порядок обмена данными
В общем случае обе базы данных являются рабочими, т.е. документы вводятся, изменяются в обеих базах. В нашем случае рабочая база только одна и данные двигаются только в одном направлении.
Полный цикл обмена состоит из следующих этапов:
- a) Выгрузка в главной ИБ данных, измененных после последнего обмена данных.
- b) Передача выгруженных данных в центральный офис;
- c) Загрузка данных в копию ИБ;
- d) Выгрузка данных из копии ИБ (выгружаются подтверждения о приеме данных);
- e) Передача результата обмена в филиал;
- f) Загрузка файла обмена в главную базу для подтверждения приема изменений в копии ИБ.
Для проверки обмена выполним цикл обмена вручную. Зарегистрируемся в исходной ИБ. Сделаем изменение в ИБ, например введем новую запись в справочник «Номенклатура»:
Откроем план обмена «Полный». Встанем на строку «Копия БП». Нажмем на значок «Записать изменения». Появится окно для выбора папки, в которую будут сохраняться файлы выгрузки и загрузки. Лучше создать для этого отдельную папку с понятным именем, например «Обмен». Автоматически сформируется имя файла выгрузки «Message_Б01_Б02.zip». По имени можно понять, что этот файл предназначен для передачи из узла «Б01» в узел «Б02». Жмем «ОК».
В центральном офисе заходим в ИБ, открываем план обмена «Полный», встаем на строчку «Главный узел». Жмем на значок «Прочитать изменения», указываем путь к файлу обмена. Жмем «ОК»:
Можно проверить, что новая переданная запись попала в справочник «Номенклатура».
Для того, чтобы рабочая ИБ «знала», что обмен произведен успешно, необходимо послать подтверждение успешного обмена. Если этого не сделать, то при следующем обмене из филиала произойдет повторная выгрузка неподтвержденных объектов.
В центральном офисе делаем выгрузку ИБ. Жмем на значок «Записать изменения». В указанную ранее папку запишется файл с автоматически созданным именем «Message_Б02_Б01.zip». Название говорит, что этот файл предназначен для главного узла «Б01» от подчиненного узла «Б02». Жмем «ОК». Происходит выгрузка указанного файла. В этом файле содержится подтверждение успешного приема изменений основной ИБ.
Таким образом, вручную был проверен механизм обмена между двумя удаленными ИБ.
3. Настройка регулярного обмена
Такой обмен очень трудоемок, поэтому в 1С имеются средства для автоматизации процедур обмена. Для упрощения обмена необходимо на каждом узле зайти в основном меню программы «Сервис / Распределенная информационная база (РИБ) / Настроить узлы РИБ».
В появившемся окне добавить строку и заполнить ее. Например, заполним строку в главном узле:
Теперь при нажатии на значок «Выполнить обмен по текущей настройке» произойдет загрузка и выгрузка данных для подчиненного узла.
Для автоматического запуска заданий обмена необходимо настроить расписание на закладке «Автообмен». Расписание автообмена следует хорошо продумать, т.к. с выгрузками из базы данных нужно синхронизировать файловый обмен между территориями. Кроме того, в нашем случае филиал и центральный офис находятся в разных часовых поясах, что накладывает дополнительные сложности в синхронизации.
Для автоматического запуска заданий необходима дополнительная настройка в меню «Предприятие / Настройка параметров учета / Обмен данными». Необходимо заполнить эту закладку.
Префикс необходим, если в подчиненном узле происходит ввод документов. Документам при обмене будет присваиваться префикс. Для автоматического запуска заданий обязательно необходимо ввести пользователя и интервал опроса. Обмен будет происходить в сеансе указанного пользователя, т.е. необходимо запустить программу с авторизацией. Пример настроек для файловой ИБ:
Аналогично нужно настроить все подчиненные узлы. В нашем случае это узел «Копия БП» в центральном офисе.
4. Выполнение регулярного обмена
Для выполнения регулярного обмена необходимо выполнить следующую последовательность действий:
- a) Войти на главном узле (в филиале) в программу под именем пользователя, указанного в настройках параметров учета (Любимов). После успешного входа процедура обмена будет запускаться через указанный интервал. В тестовом примере - через 600 секунд. При обмене вначале происходит чтение входного файла обмена от подчиненного узла, а затем запись новых изменений ИБ в выходной файл обмена. Если входной файл обработан успешно, он удаляется из папки обмена.
- b) Затем необходимо произвести файловый обмен между центральным офисом и филиалом. Новый выходной файл будет передан в центральный офис. Файловый обмен необходимо синхронизировать с интервалом регламентных заданий в программе. Если в программе интервал составляет 1 час, то файловый обмен должен происходить чаще, например каждые 30 минут.
- c) В центральном офисе запущенная программа также будет пытаться выполнить регламентное задание через указанный интервал. Здесь также вначале происходит чтение полученного файла, а затем запись в выходной файл. Т.к. ввод данных идет только в филиале, то в выходной файл заносятся квитанции о получении данных. При удачном чтении входной файл, полученный из филиала, будет удален.
- d) При очередном сеансе связи происходит обмен файлами между обменными папками.
- e) Т.к. программа в филиале уже открыта, то при очередном автоматическом запуске регламентного задания произойдет очередной обмен, т.е. повторение пункта а).
Специальные предложения







Для тех, кто первый раз делает РИБ - пригодится.
зы. ставлю + за много буков и картинки. Автор - чайник, который должен читать и учиться, а не писать статьи. ЕЩЕ ОЧЕНЬ РАНО Вам браться за перо. Цицата:" . В центральном офисе хотят иметь актуальную копию базы данных филиала". Обращаю Ваше внимание, что при распределенке нет копии баз данных филиала (их обычно называют информационными базами), а все работают в одной (единой ИБ). Комментировать остальное просто нет времени и желания. (3) я думаю, что на данном уровне изложения - такая терминология впролне допустима. особенно если для пользователя периферийной базы эта РАСПРЕДЕЛЕННАЯ БАЗА выглядит как отдельная база, связанная с ДРУГОЙ (ЦЕНТРАЛЬНОЙ) БАЗОЙ только посредством автообменов.. (0) Автор старался писал - плюс заслужил
(3) Ну все были чайниками. НО согласен что формулировка должна быть максимально точной дабы не вводить в заблуждение.
(0) Картинки у меня почему-то отсутствуют. :(
"В нашем случае рабочая база только одна и данные двигаются только в одном направлении." - Не увидел в описании где это настраивается.
Попробуйте в базе с 16000 доков за месяц сделать групповое перепроведение за месяц и потом запустите типовой обмен РИБ.
Я думал будет описание реализации обмена только документами БЕЗ ДВИЖЕНИЙ, и в дальнейшем в каждой БД фоновое допроведение/удаление/распроведение документов. УРБД в 4 шага. Уже классическая статья. Не надо велописедов изобретать. Тем более так плохо их описывать. Даже с выходом 8.2 продолжаю всем советовать терминальный доступ.
РИБ требует очень прямых рук каждый день и имеет ряд минусов. Ну наехали.
Старался человек, с людьми поделиться знаниями хотел. Стока букафф натыкать.
Плюс.
Хм. А чем это отличается от статьи на ИТСе, которая еще на 8.0 начала выходить? Там то же самое с картинками и примерами. В 2006м году видел ее на ИТСе. Автору плюс авансом. Ждём описания того, какие действия надо предпринять, если была изменена структура конфигурации. Как заметил
Cyberboy в первом посту, это важно !
(12) При работе с распределенной информационной базой (РИБ) иногда возникает ошибка: «Конфигурация узла распределенной ИБ не соответствует ожидаемой!»
На диске ИТС есть статья «Обработка ошибок, возникающих при обмене данными в РИБ». В этой статье перечислены ошибки, их источники.
> Начат обмен данными по настройке "Ежедневный" (9:02:11).
!! Ошибка при чтении изменений при обмене РИБ: Ошибка при вызове метода контекста (ПрочитатьИзменения): Конфигурация узла распределенной ИБ не соответствует ожидаемой!
!! Чтение данных из файла обмена завершено с ошибками!
> Запись изменений текущей информационной базы в файл обмена завершилась успешно.
> Обмен данными по настройке "Ежедневный" завершен (9:06:50).
При этом главный узел «понимает», что нужно обновить конфигурацию подчиненного узла и добавит в файл обмена изменения в конфигурации.
> Начат обмен данными по настройке "Дневной" (9:17:07).
!! Ошибка при чтении изменений при обмене РИБ: Ошибка при вызове метода контекста (ПрочитатьИзменения): Из главного узла распределенной информационной базы получены изменения конфигурации.
Необходимо выполнить обновление конфигурации базы данных.
Обновление может быть выполнено в режиме Конфигуратор.
!! Чтение данных из файла обмена завершено с ошибками!
> Запись изменений текущей информационной базы в файл обмена завершилась успешно.
> Обмен данными по настройке "Дневной" завершен (9:32:46).
> Начат обмен данными по настройке "Дневной" (9:58:37).
> Чтение данных из файла обмена успешно завершено.
> Запись изменений текущей информационной базы в файл обмена завершилась успешно.
> Обмен данными по настройке "Дневной" завершен (10:12:56).
> Начат обмен данными по настройке "Ежедневный" (10:26:27).
> Чтение данных из файла обмена успешно завершено.
> Запись изменений текущей информационной базы в файл обмена завершилась успешно.
> Обмен данными по настройке "Ежедневный" завершен (10:26:52).
Такие операции необходимо проделать для каждого подчиненного узла.
Механизм РИБ — механизм распределенных информационных баз - это когда у вас есть главная база и подчиненная(ые). Главная база может быть только одна, подчиненных может быть много. Каждая подчиненная база может иметь свои подчиненные базы, для которых она будет главной.
Вот посмотрим на картинку из первой ссылки по запросу в Яндексе:
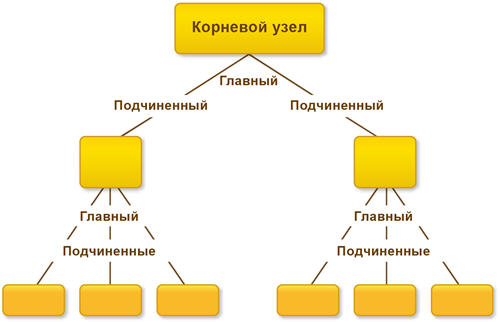
РИБ используется для обмена данными. Причем не только теми данными, с которыми работает пользователь, но и данными изменения конфигурации. То есть РИБ позволяет передавать изменения конфигурации. Но изменить конфигурацию можно только в главной базе!
Визуализируем:
У нас большая компания и много филиалов. Есть доработанная УНФ, которую мы гордо называем УБФ(Управление Большой Фирмой). Но мы решили, что хватит терпеть то, что все филиалы имеют доступ к документам всех филиалов и каждому филиалу решили сделать отдельную базу, которую синхронизировать с нашей основной базой для передачи данных. Что ж, можно. Сделали.
И внезапно мы решили изменить картинку, которая появляется при входе в базу, захотели поместить туда логотип нашей фирмы, а почему бы и нет?
Как запилить картинку во все базы всех филиалов? Ну при текущем варианте, что у всех филиалов отдельная база, только руками. Руками специалистов, которые умеют заходить в конфигуратор и знают что нужно там нажать.
А вот если бы мы сделали подчиненные базы для филиалов, то есть использовали РИБ, то и данными бы обменивались, как при обычной синхронизации, и картинка бы сама добавилась во все "базы-дочки". Однако, в конфигуратор зайти бы все-таки пришлось, но только чтобы нажать кнопочку "Обновить конфигурацию базы данных", вот картинка:

Как создать подчиненную базу, на пальцах:
я буду использовать Управление торговлей, редакция 11 (11.4.13.275), но способ, в целом, одинаковый во всех типовых конфигурациях.
1) Сначала проделаем шаги, как при настройке обычной синхронизации:

2) . поставим галочку, нажмем.


4) тут ознакомимся с описанием. Я выберу обычную настройку, но если бы мы следовали примеру выше, то нужно было бы выбрать "с фильтром" и там одним кликом выбрать нужный филиал.


6) Указываем префикс - он будет подставляться к номерам документов, чтобы можно было отличить документы дочки и основной базы.


7) в общем случае, тут ничего не надо нажимать, кроме "Записать и закрыть".

8) А вот теперь создаем нашу новую подчиненную базу:

9) указываем место, куда ее покладем.




10) Зайдем в нашу новую подчиненную базу и закончим настройки синхронизации(синхронизация уже создалась, так как использовали РИБ, но нужно указать каталог для обмена выбрав "Настройки подключения")

(обратите внимание на верхний левый угол окна программы, там название базы, он отличается от предыдущих, так как это "дочка")
Кстати, в новой базе все пользователи будут выключены, пароли сброшены, нужно включить руками:

В общем-то ВСЕ.
Подчиненная база создана!
Теперь, когда наши программисты что-нибудь улучшат, эти улучшения прилетят в подчиненные базы сами.
Вот что-то изменили в основной базе:

нам нужно перенести изменения в базы-дочки.
Для этого запускаем главную базу в режиме 1С:Предприятие, то есть в пользовательском интерфейсе, заходим в настройки синхронизации, жмем выделенную кнопку:

После того, как синхронизация закончится, заходим в базу дочку и так же жмем "Синхронизировать", база загрузит данные и напишет:


После нажатия на Далее база закроется и начнет устанавливать обновления.

Когда обновы установятся, база начнет запускаться и сообщит нам следующее:

Это означает, что не обновлена конфигурация базы данных. Та самая маленькая кнопка в конфигураторе и это именно та причина, почему придется ОДИН раз зайти в конфигуратор. Что ж, зайдем в конфигуратор базы-дочки и нажмем эту кнопку, заодно вообще посмотрим что-да-как там, мы ж там еще не были.
Откроем конфигурацию и вот что увидим
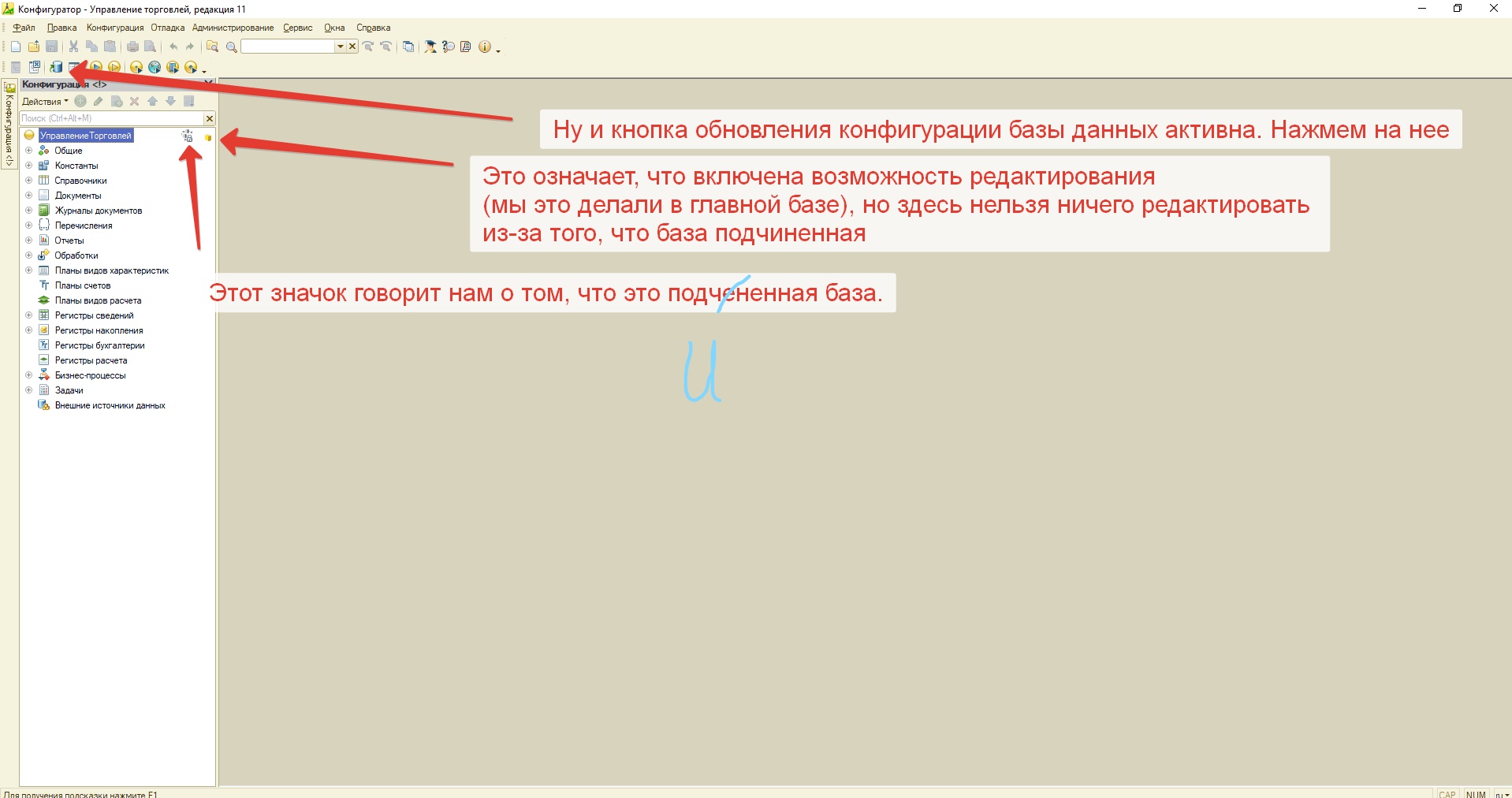
Нажмем на "Обновить конфигурацию базы данных".
Увидим список изменений, которые прилетели с обновлениями:

И вот эти обновления появились в подчиненной базе.

Теперь необходимо запустить базу в пользовательском режиме, чтобы выполнились обработчики обновления.
Несколько правил:
1) Все узлы, кроме одного, должны иметь по одному главному узлу и один узел не будет иметь главного узла - это корневой узел.
2) Конфигурация может быть изменена только в узле, не имеющем главного узла (то есть в корневом).
3) Изменения конфигурации будут передаваться от главного к подчиненным узлам.
4) Разрешение коллизий так же будет производиться исходя из отношений "главный - подчиненный" - если изменения сделаны одновременно и в главном и в подчиненном узлах, то приняты будут изменения главного узла.
5) Сделать подчиненный узел в распределенной базе можно разными способами, но создание начального образа является рекомендуемым.
А теперь то, ради чего все писалось.
Как подчиненную базу сделать обычной(нормальной, отдельной, как хотите).
Я опишу только тот способ, которым пользуюсь. Это моя шпаргалка. Но он не единственный.
1) Заходим в свойства ярлыка запуска окна 1С:Предприятие:

2) В поле "Объект" дописываем:
DESIGNER /F"Путь до базы" /N"Имя Пользователя в базе" /P"Пароль пользователя" /ResetMasterNode
Редкая современная продакшн система обходится без репликации баз данных. Это мощный инструмент на пути к повышению производительности и отказоустойчивости системы, и современному разработчику очень важно иметь хотя бы общее представление о репликации. В данной статье я поделюсь базовыми знаниями о репликации, и покажу простой пример настройки репликации в MySQL с помощью Docker.

Что такое репликация, и зачем она нужна
Само по себе, понятие репликации означает процесс синхронизации нескольких копий объекта. В нашем случае, таким объектом является сервер БД, а наибольшую ценность представляют собой сами данные. Если мы имеем два и более серверов, и любым возможным способом поддерживаем синхронизированный набор данных на них — мы реализовали репликацию системы. Даже ручной вариант с mysqldump -> mysql load — это также репликация.
Стоит понимать, что сама по себе репликация данных не имеет ценности, и является лишь инструментом решения следующих задач:
- повышение производительности чтения данных. С помощью репликации мы сможем поддерживать несколько копий сервера, и распределять между ними нагрузку.
- повышение отказоустойчивости. Репликация позволяет избавиться от единственной точки отказа, которой является одиночный сервер БД. В случае аварии на основном сервере, есть возможность быстро переключить нагрузку на резервный.
- распространение данных. В современную эпоху глобализации ваше приложение может обслуживать пользователей со всего мира, и мы хотим, чтобы жители и Сиднея, и Хельсинки имели минимальную задержку доступа к нему.
- распределение нагрузки. В случае, если БД обслуживает запросы разных типов (быстрые и легкие, медленные и тяжелые), может иметь смысл развести эти запросы по разным серверам, для увеличения эффективности работы каждого типа.
- тестирование новых конфигураций. С помощью репликации есть возможность проведения тестирования новых версий сервера БД, изменения параметров конфигурации, и даже изменения типов хранилища данных.
- резервное копирование. С помощью репликации есть возможность делать механизмы резервного копирования более гибкими и вносить меньше негативных эффектов в работающую систему.
Как MySQL реплицирует данные
Процесс репликации подразумевает собой распространение изменений данных с главного сервера (обычно он называется как мастер, master), на один или более подчиненных серверов (слейв, slave). Существуют и более сложные конфигурации, в частности с несколькими мастер-серверами, но для каждого изменения на конкретном мастер-сервере остальные мастера условно становятся слейвами, и потребляют эти изменения.
В общем виде, репликация в MySQL состоит из трех шагов:
- Мастер-сервер записывает изменения данных в журнал. Этот журнал называется двоичным журналом (binary log), а изменения — событиями двоичного журнала.
- Слейв копирует изменения двоичного журнала в свой, который называется журналом ретрансляции (relay log).
- Слейв воспроизводит изменения из журнала ретрансляции, применяя их к собственным данным.
Виды репликации
Существует два принципиально разных подхода к репликации: покомандная и построчная. В случае покомандной репликации, в журнал мастера протоколируются запросы изменения данных (INSERT, UPDATE, DELETE), а слейвы в точности воспроизводят те же команды у себя. При построчной же репликации в журнале окажутся непосредственно изменения строк в таблицах, и эти же фактические изменения применятся затем на слейве.
Как нет серебряной пули, так и каждый из этих методов имеет свои преимущества и недостатки. Покомандная репликация проще в реализации и понимании, снижает нагрузку на мастер и на сеть. Но тем не менее, покомандная репликация может приводить к непредсказуемым эффектам, при использовании недетерминированных функций, таких как NOW(), RAND(), и т.д. Могут быть также проблемы, вызванные рассинхронизацией данных между мастером и слейвом. Построчная же репликация приводит к более прогнозируемым результатам, так как фиксируются и воспроизводятся фактические изменения данных. Тем не менее этот метод может значительно увеличивать нагрузку на мастер-сервер, которому приходится фиксировать каждое изменение в журнале, и на сеть, через которую эти изменения распространяются.
В MySQL поддерживаются оба способа репликации, а дефолтный (можно сказать, что и рекомендуемый) изменялся в зависимости от версии. В современных версиях, например MySQL 8, по умолчанию используется построчная репликация.
Второй принцип разделения подходов к репликации — количество мастер-серверов. Наличие одного мастер сервера подразумевает, что только он принимает изменения данных, и является неким эталоном, с которого уже распространяются изменения на множество слейвов. В случае же с мастер-мастер репликацией мы получаем как и некоторый профит, так и проблемы. Один из плюсов, например, то, что мы можем давать удаленным клиентам из тех же Сиднея и Хельсинки одинаково быструю возможность записывать свои изменения в базу. Из этого исходит и главный недостаток, если оба клиента одновременно изменили одни и те же данные, чьи изменения считать окончательными, чью транзакцию коммитить, а чью откатывать.
Также, стоит отметить, что наличие мастер-мастер репликации в общем случае не может увеличить производительность записи данных в системе. Представим, что наш единственный мастер может обрабатывать до 1000 запросов в единицу времени. Добавив к нему реплицируемый второй мастер, мы не сможем обрабатывать по 1000 запросов на каждом из них, так как кроме обработки “своих” запросов, им придется применять изменения, сделанные на втором мастере. Что в случае покомандной репликации сделает суммарно возможную нагрузку на оба не больше, чем на самый слабый из них, а с построчной репликацией эффект не совсем предсказуемый, может быть как положительный, так и отрицательный, в зависимости от конкретных условий.
Пример построения простой репликации в MySQL
А сейчас настало время создать простую конфигурацию репликации в MySQL. Для этого мы будем использовать Docker и MySQL образы из dockerhub, а также базу данных world.
Для начала, запустим два контейнера, один из которых позже настроим как мастер, а второй — как слейв. Объединим их в сеть, чтобы они могли обращаться друг к другу.
Для мастер контейнера указано подключение volume c дампом world.sql, для того, чтобы имитировать наличие некоторой начальной базы на нем. При создании контейнера, mysql загрузит и выполнит sql скрипты, размещенные в директории docker-entrypoint-initdb.d.
Для работы с конфигурационными файлами, нам потребуется текстовый редактор. Можно использовать любой удобный, я предпочитаю vim.
Первым делом, создадим учетную запись на мастере, которая будет использоваться для репликации:
Далее, изменим конфигурационные файлы для мастер-сервера:
В файл my.cnf в секции [mysqld] необходимо добавить следующие параметры:
При включении/выключении двоичного журнала необходима перезагрузка сервера. В случае с Docker перезагружается контейнер.
Убедимся, что двоичный журнал включен. Конкретные значения, такие как имя файла и позиция, могут отличаться.
Для того, чтобы начать репликацию данных, необходимо “подтянуть” слейв до состояния мастера. Для этого, нужно временно заблокировать сам мастер, чтобы сделать слепок актуальных данных.
Далее, с помощью mysqldump сделаем экспорт данных из базы. Конечно, в данном примере можно использовать тот же world.sql, но приблизимся к более реалистичному сценарию.
После этого, необходимо еще раз выполнить команду SHOW MASTER STATUS, и запомнить или записать значения File и Position. Это, так называемые координаты двоичного журнала. Именно от них мы далее укажем стартовать слейву. Начиная с MySQL 5.6 стало возможным использование глобальных идентификаторов транзакций GTID вместо координат в виде файл-позиция. Это упростило настройку репликации, а также повысило стабильность ее работы. Но рассмотрение этой темы выходит за рамки данной статьи, и с ней можно ознакомиться в документации.
Теперь можем снова разблокировать мастер:
Мастер настроен, и готов реплицироваться на другие сервера. Перейдем теперь к слейву. Первым делом, загрузим в него дамп, полученный с мастера.
А затем изменим конфиг слейва, добавив параметры:
После этого перезагрузим слейв:
И теперь нам нужно указать слейву, какой сервер будет являться для него мастером, и откуда начинать реплицировать данные. Вместо MASTER_LOG_FILE и MASTER_LOG_POS необходимо подставить значения, полученные из SHOW MASTER STATUS на мастере. Эти параметры вместе называются координатами двоичного журнала.
Запустим воспроизведение журнала ретрансляции, и проверим статус репликации:
Если все прошло успешно, ваш статус должен иметь аналогичный вид. Ключевые параметры здесь:
- Slave_IO_State, Slave_SQL_State — состояние IO потока, принимающего двоичный журнал с мастера, и состояние потока, применяющего журнал ретрансляции соотвественно. Только наличие обоих потоков свидетельствует об успешном процессе репликации.
- Read_Master_Log_Pos — последняя позиция, прочитанная из журнала мастера.
- Relay_Master_Log_File — текущий файл журнала мастера.
- Seconds_Behind_Master — отставание слейва от мастера, в секундах.
- Last_IO_Error, Last_SQL_Error — ошибки репликации, если они есть.
И проверить, появились ли они на слейве.
Отлично! Внесенная запись видна и на слейве. Поздравляю, теперь вы создали свою первую репликацию MySQL!
Заключение
Надеюсь, что в рамках данной статьи мне удалось дать базовое понимание процессов репликации, ознакомить с применением данного инструмента, и попробовать самостоятельно реализовать простой пример репликации в MySQL. Тема репликации, и ее практического применения крайне обширна, и если вас заинтересовала данная тема, могу порекомендовать к изучению следующие источники:
Читайте также: