
Pcsd linux что это
Обновлено: 05.07.2024
Подготовка серверов
Обновляем систему.
Настраиваем время.
Необходимо, чтобы на всех нодах было одинаковое время.
Устанавливаем утилиту для синхронизации даты и времени:
yum install ntpdate
Настраиваем синхронизацию по расписанию:
Выставляем нужный часовой пояс:
\cp /usr/share/zoneinfo/Europe/Moscow /etc/localtime
* в моем примере московское время.
Настройка брандмауэра.
Выполняется следующими 2-я командами:
firewall-cmd --permanent --add-service=high-availability
Установка пакетов для работы с кластером
Установка выполняется на всех узлах следующей командой:
yum install pacemaker pcs resource-agents
Если возникнут проблемы, читаем подробную инструкцию по установке Pacemaker.
Задаем пароль для учетной записи hacluster, которая была создана автоматически при установке pacemaker:
Разрешаем сервис pcsd и запускаем его:
systemctl enable pcsd
systemctl start pcsd
Сборка кластера
Настройка выполняется на одном из узлов.
Первым делом, авторизовываемся на серверах следующей командой:
pcs cluster auth node1 node2 -u hacluster
* где node1 и node2 — имена серверов, hacluster — служебная учетная запись (создана автоматически при установке пакетов).
pcs cluster setup --force --name NLB node1 node2
* где NLB — название для кластера; node1 и node2 — серверы, которые должны входить в кластер.
После успешного выполнения команды мы увидим, примерно, следующее:
Synchronizing pcsd certificates on nodes node1, node2.
node2: Success
node1: Success
* также, будет создан конфигурационный файл /etc/corosync/corosync.conf.
Разрешаем автозапуск и запускаем созданный кластер:
pcs cluster enable --all
pcs cluster start --all
* опция --all говорит, что необходимо выполнить команду для всех нод, к которым мы подключились (вместо этой опции можно перечислить ноды вручную).
При использовании 2-х нод (как в данном примере) отключаем stonith (нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы) и кворум:
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
Просмотреть состояние можно командой:
Настройка виртуального IP
Рассмотрим самый распространенный вариант использования Pacemaker. Он заключается в использовании виртуального IP-адреса, который будет назначаться активному узлу кластера.
Для этого создаем ресурс командой:
pcs resource create virtual_ip ocf:heartbeat:IPaddr2 ip=192.168.0.15 cidr_netmask=24 op monitor interval=60s
* где virtual_ip — название ресурса (может быть любым); 192.168.0.15 — виртуальный IP, который будет назначен кластеру; 24 — префикс сети (соответствует маске 255.255.255.0); 60s — критическое время простоя, которое будет означать недоступность узла.
Мы должны увидеть, примерно такую строку:
virtual_ip (ocf::heartbeat:IPaddr2): Started node1
Для проверки, перезагружаем активную ноду (node1) командой:
Через небольшой промежуток времени должен смениться узел с virtual_ip:
virtual_ip (ocf::heartbeat:IPaddr2): Started node2
Для смены активной ноды ресурса, вводим команду:
pcs resource move virtual_ip node1
Отказоустойчивость сервисов
Кластеризация по виртуальному IP-адресу позволит обеспечить высокую доступность на уровне работы сервера. Но если необходимо более тонкая настройка, позволяющая менять активную ноду при отказе службы, выполняем действия, описанные ниже.
Список всех поддерживаемых сервисов можно посмотреть командой:
crm_resource --list-agents ocf
Разберем кластеризацию на базе postfix.
Подключаемся к кластеру и создаем следующий ресурс:
pcs cluster auth node1 node2 -u hacluster
pcs resource create postfix ocf:heartbeat:postfix op monitor interval=30s timeout=60s
Удаление ноды
При необходимости исключить одну из нод кластера, выполняем следующую команду:

Сам себе аудитор, или безопасность собственными силами
Перед администраторами, а уж тем более перед аудиторами ИБ часто встают задачи проверить защищенность большого количества хостов за очень короткое время. И конечно, для решения этих задач в Enterprise-сегменте существуют специализированные инструменты, к примеру такие, как сетевые сканеры безопасности. Уверен, что все они — от open sources движка OpenVAS до коммерческих продуктов типа Nessus или Nexpose — известны нашему читателю. Однако этот софт обычно используется, чтобы искать устаревшее и потому уязвимое ПО и затем запустить патч-менеджмент. К тому же не все сканеры учитывают некоторые специфические особенности встроенных механизмов защиты Linux и других open sources продуктов. Ну и не в последнюю очередь значение имеет цена вопроса, ведь коммерческие продукты в состоянии позволить себе разве что компании, выделяющие под это дело бюджеты.
Именно поэтому сегодня речь пойдет о специализированном наборе свободно распространяемых утилит, которые могут диагностировать текущий уровень защищенности системы, оценить потенциальные риски, к примеру «лишние сервисы», торчащие в интернет, или небезопасный конфиг по умолчанию, и даже предложить варианты исправления найденных недостатков. Еще одно преимущество использования этих тулз заключается в возможности тиражировать типовые сценарии проверки фермы из любого количества Linux-систем и формировать документально подтвержденную базу тестов в виде логов и отдельных репортов.
Практические аспекты аудита защищенности
Если посмотреть глазами аудитора, то подход к тестированию можно разделить на два типа.
Первый — это соответствие так называемым compliance-требованиям, здесь проверяется наличие обязательных элементов защиты, прописанных в каком-либо международном стандарте или «best practice». Классический пример — требования PCI DSS для платежных ИТ-систем, SOX404, NIST-800 series, MITRE.
Второй — это сугубо рациональный подход, основанный на вопросе «А что еще можно сделать, чтобы усилить защищенность?». Тут нет обязательных требований — только твои знания, светлая голова и умелые руки. К примеру, это обновление версии ядра и/или пакетов приложений, включение шифрования томов, форсирование SELinux, настройка файрвола iptables.
Все, что относится ко второму подходу, принято называть специальным термином Hardening, что еще можно определить как «действия, направленные на усиление уровня исходной защищенности операционной системы (или программы) преимущественно штатными средствами».
Соответствие compliance-требованиям, как правило, проверяют при подготовке к прохождению обязательного аудита типа PCI DSS или другого сертификационного аудита. Мы же больше уделим внимание Hardening-составляющей. Все крупные разработчики предлагают для своих продуктов Hardening Guidelines — руководства, содержащие советы и рекомендации, как усилить защищенность, учитывая штатные механизмы безопасности и специфику софта. Так, подобные руководства есть у Red Hat, Debian, Oracle, Cisco.
Hardening — это термин из мира ИБ, который обозначает процесс обеспечения безопасности системы (программы) за счет снижения ее уязвимости и, как правило, с использованием только штатных утилит или механизмов защиты.
Кстати, на Хакере уже была схожая статья про настройку опций Hardening, но тогда речь шла именно о настройке. Мы же сначала почекаем нашу систему с помощью специальных утилит, то есть проведем аудит ИБ, оценим текущий уровень защиты, а потом уже накрутим туда security option, если необходимо. Ну или еще как вариант: если сервер уже оттюнингован с точки зрения безопасности, наши тулзы смогут это проверить и, возможно, подсказать, что же можно сделать еще.
Обзор инструментов
1. Lynis — auditing, system hardening, compliance testing
Lynis — первая в нашем списке инструментов и, пожалуй, самая навороченная тулза для аудита Linux-систем. При этом она очень простая в использовании и очень наглядная — все тесты и их результаты выводятся на экран. Утилита сканирует настройки текущего уровня безопасности и определяет состояние защищенности (hardening state) машины. Найденные тревожные сигналы и важные алерты безопасности выводятся в консоль терминала и отдельно в лог-файл, сгруппированные по блокам. Кроме сведений о безопасности, Lynis также поможет получить общесистемную информацию, информацию об установленных пакетах и возможных ошибках конфигурации, обновлениях ядра.
Разработчиками заявлена поддержка огромного числа операционных систем: от Arch, BackTrack, Kali до разновидностей Debian/Ubuntu, RHEL/CentOS, SuSE, BSD-семейства (FreeBSD, NetBSD, OpenBSD, DragonFly BSD), а также более экзотичных HPUX, Solaris 10+, TrueOS и macOS.
Вся документация с более подробным описанием и примерами использования доступна в разделе Lynis Documentation на официальном сайте CISOfy. Если не хочешь ограничиваться предлагаемыми тестами, есть возможность разработки собственных. Более подробно об этом написано в разделе Lynis Software Development Kit. Ну и для тех, кто еще сомневается, устанавливать или нет утилиту, разработчики подготовили небольшое demo, поясняющее, как происходит установка и первичный запуск.
Кроме бесплатной версии, которую мы и будем чуть ниже использовать, разработчики предлагают решение Enterprise-уровня. В этом случае к стандартной поставке добавляется веб-интерфейс для администрирования, опциональные дашборды, дополнительная документация (hardening snippets) и развернутый план корректировки выявленных нарушений. И это еще не все, данное решение ко всему прочему можно получить в виде облачного сервиса (Software-as-a-Service).
Lynis выполняет сотни отдельных тестов, чтобы определить состояние защищенности системы. Сама проверка защищенности заключается в выполнении набора шагов от инициализации программы до генерации отчета.
Поскольку Lynis весьма гибкий и многопрофильный инструмент, она используется для различных целей. К примеру, типовые варианты использования Lynis включают:
- аудит безопасности (типовой сценарий, задаваемый пользователем);
- тестирование на соответствие требованиям (например, PCI DSS, HIPAA, SOX404, OpenSCAP, NSA);
- обнаружение уязвимостей (устаревшее ПО);
- режим Penetration testing (попытка эскалации привилегий);
- улучшение системы (незадействованные твики ядра, демонов и прочего).
Установить утилиту можно несколькими способами — как с помощью загрузки из хранилища GitHub:
так и установкой из репозитория Debian/Ubuntu:
И для RPM-ориентированных дистрибутивов (предварительно добавив соответствующие репозитории):
Установка на macOS:
Чтобы запустить Lynis, достаточно указать хотя бы один ключ. К примеру, для запуска всех имеющихся тестов следует указать ключ -c (check all, проверить все):
Инициализация тестов
Результаты тестов из группы System Tool and Boot & Services
Результаты тестов из группы Kernel and Memory & Process auditing
Результаты тестов из группы User and Group & Authentication
Перед аудитом всегда полезно проверить, доступна ли новая версия Lynis:
У утилиты Lynis, помимо стандартного, существует еще один режим — непривилегированного запуска:
Если же ты хочешь поместить имя аудитора, запустившего тестирование, просто добавь параметр -auditor <name> :
На любом этапе аудита процесс проверки может быть продолжен (Enter) либо принудительно прекращен (Ctrl+C). Результаты выполненных тестов будут писаться в журнал Lynis в /var/log/lynis.log . Учти, что журнал будет перезаписываться при каждом следующем запуске утилиты.
Сохрани этот скрипт в каталог /etc/cron.monthly/lynis . И не забудь добавить пути для сохранения логов ( /usr/local/lynis и /var/log/lynis ), иначе возможна некорректная работа.
Можно посмотреть список всех доступных для вызова команд:
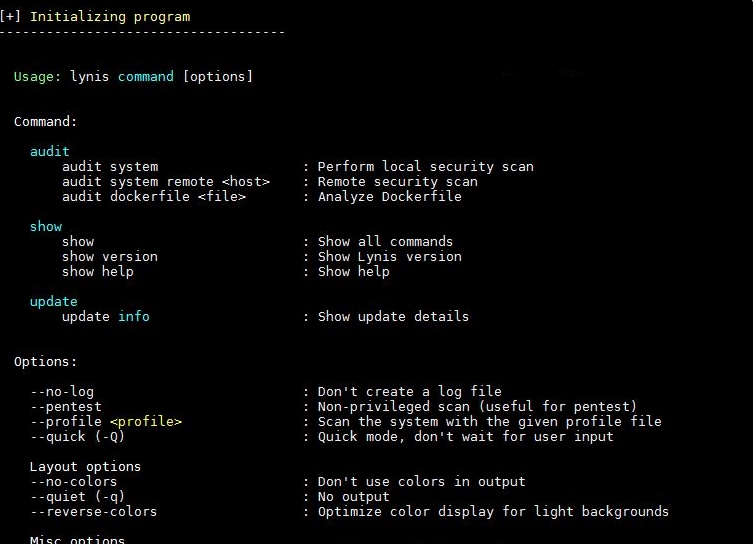
Вывод доступных команд
Особо любопытные могут глянуть настройки из конфига по умолчанию:
Краткий инструктаж по работе с утилитой:
Варианты возможных статусов по результатам проверки ограничиваются следующим списком: NONE, WEAK, DONE, FOUND, NOT_FOUND, OK, WARNING.
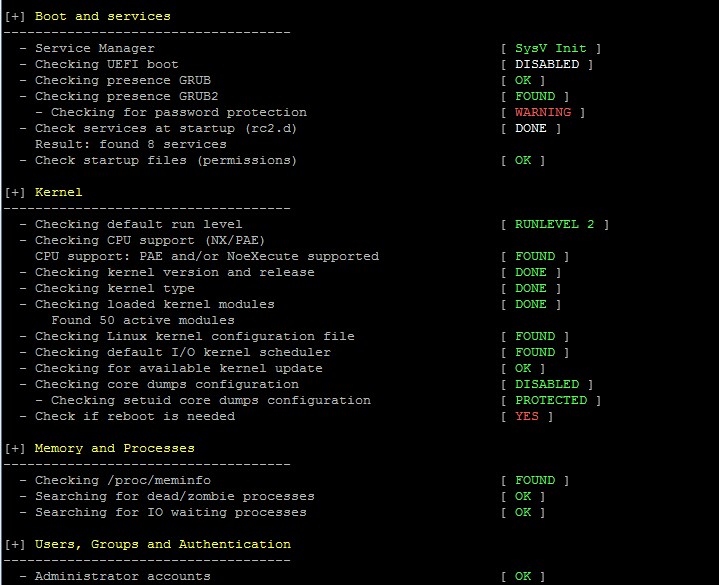
Пример вывода статусов
Запуск отдельных тестов в Lynis
На практике бывает необходимо провести лишь некоторые тесты. К примеру, если твой сервак выполняет только функции Mail Server или Apache. Для этого мы можем использовать параметр -tests . Синтаксис команды выглядит следующим образом:
Если тебе сложно разобраться из-за большого количества идентификаторов тестов, то ты можешь использовать групповой параметр -test-category . С помощью данной опции Lynis запускает идентификаторы только тех тестов, которые входят в определенную категорию. Например, мы планируем запустить тесты брандмауэра и ядра:
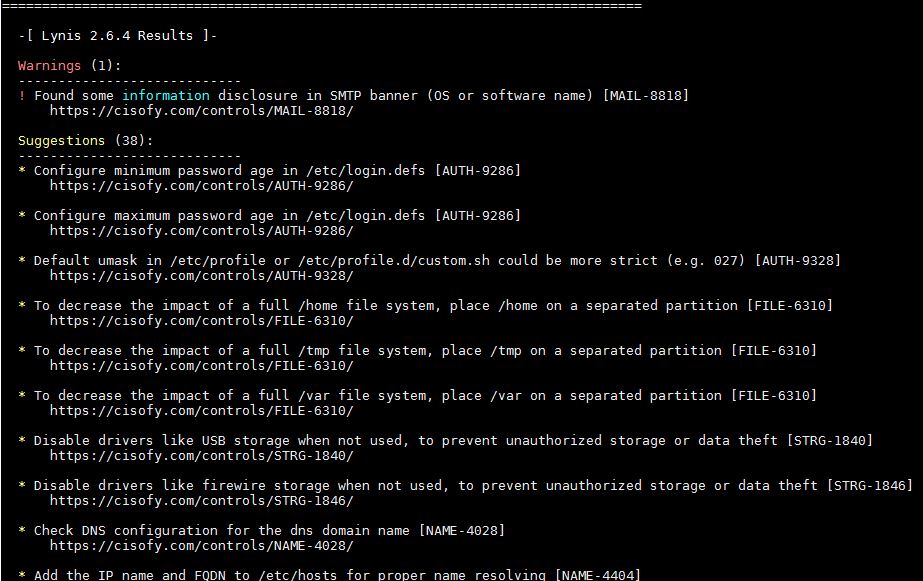
Пример запуска отдельных тестов
Список всех доступных тестов можно посмотреть в разделе Controls.
Помимо этого, функциональность Lynis расширяют различные плагины, которые можно дописывать самостоятельно, а можно подкладывать новые в существующую директорию.
Предложения по исправлению (Suggestions)
Все предупреждения (Warnings) будут перечислены после результатов. Каждое начинается с текста предупреждения, потом рядом в скобках указывается тест, который его сгенерировал. В следующей строке предлагается решение проблемы, если оно существует. По факту последняя строка — это URL-адрес, по которому ты сможешь посмотреть подробности и найти дополнительные рекомендации, как устранить возникшую проблему.
Вывод рекомендаций, как устранять найденные проблемы
Профили
Создаем и редактируем кастомный профиль:
В этом файле можно определить список тестов, которые нужно исключить из аудита Lynis. Например:
Чтобы исключить какой-то определенный тест, используй директиву skip-test и укажи ID теста. Например, так:
Оценка hardening state
По результатам выполнения всех тестов в конце каждого вывода аудита утилиты (чуть ниже раздела предложений) ты найдешь раздел, который будет выглядеть приблизительно следующим образом:
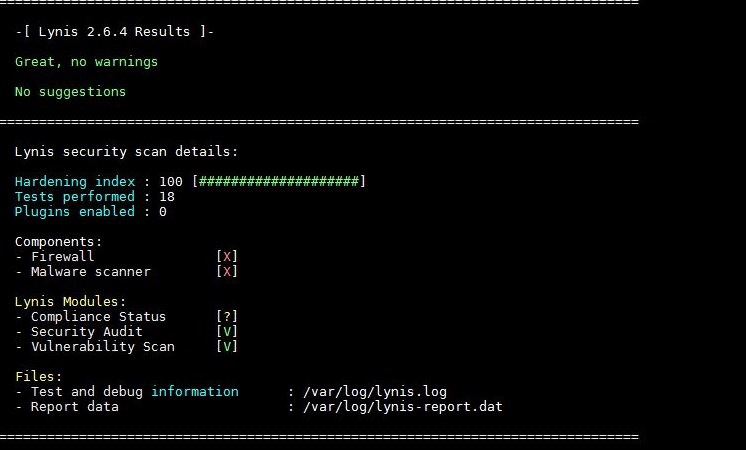
Итоговая оценка hardening state
Этот результат, выраженный числом, показывает количество пройденных тестов и индекс безопасности системы, то есть hardening index — итоговое число, с помощью которого Lynis оценивает общий уровень безопасности сервера. И очень важно не забывать, что индекс безопасности изменяется в зависимости от количества исправленных предупреждений и реализованных рекомендаций Lynis. Поэтому после фиксов повторный аудит может показать совсем другое число!
WARNING
Любые манипуляции с системой в режиме суперпользователя требуют пристального внимания и повышенной ответственности. Выполняй только те действия, которые осознаешь и в которых твердо уверен. Не пренебрегай резервными копиями и снапшотами.
2. Lunar — a UNIX security auditing tool based on several security frameworks
Lunar — это набор нативных скриптов, написанных на языке командной оболочки bash, которые тестируют целевую Linux-машину и генерируют по результатам проверки заключение аудита безопасности. Тулза основана на стандартах CIS и других мировых фреймворках по безопасности. Заявлена поддержка всех популярных систем: Linux — RHEL и CentOS с версии 5, SLES начиная с версии 10, Debian/Ubuntu, Amazon Linux, Solaris с версии 6, macOS (последние билды), FreeBSD (частично), AIX (частично) и даже ESXi.

Логотип Lunar
Кроме прочего, данная утилита поддерживает облачную платформу Amazon Web Services (AWS) и контейнеры Docker. Подробное описание всех фич, а также примеры запуска утилиты и инициации тестов приведены в документации Wiki на GitHub.
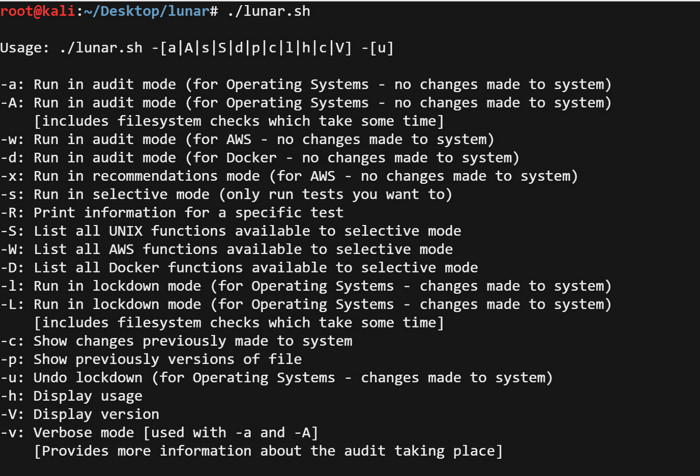
Просмотр всех параметров запуска Lunar
Запуск в режиме аудита, то есть без внесения изменений в систему:
Запуск в режиме аудита и предоставления большей информации:
Выполнять только тесты на основе оболочки:
Запуск в режиме исправления, то есть с внесением изменений в систему:
Просмотр предлагаемых изменений (твиков) системы до их внесения в конфиги:
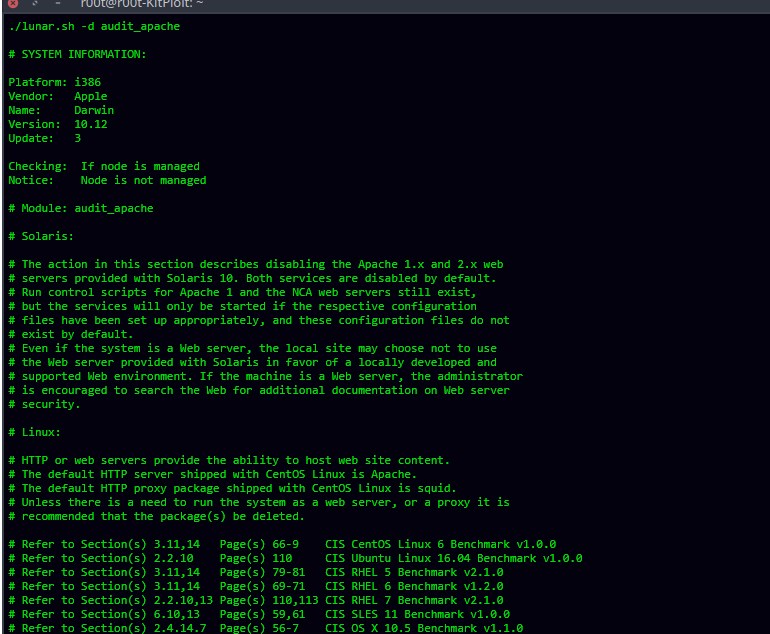
Пример запуска тестов для web-сервера Apache
3. Nix Auditor — a CIS Audit made easier
Nix Auditor — это еще один скрипт для проверки, соответствует ли безопасность Linux-систем требованиям бенчмарка CIS. Ориентирован на RHEL, CentOS и прочие RPM-дистрибутивы.
Разработчики заявляют о таких преимуществах Nix Auditor:
- скорость сканирования — провести базовую проверку ОС можно менее чем за 120 секунд и тут же получить отчет;
- точность проверки — работа утилиты проверена на разных версиях дистрибутивов CentOS и Red Hat;
- настраиваемость — исходники с документацией к программе лежат на GitHub, поэтому код легко настраивается в соответствии с типом ОС и набором элементов системы, которые необходимо проверить;
- простота использования — достаточно сделать стартовый скрипт исполняемым, и тот готов к проверке.
Пример выполнения команд для загрузки утилиты с GitHub-хранилища и последующего запуска скрипта:
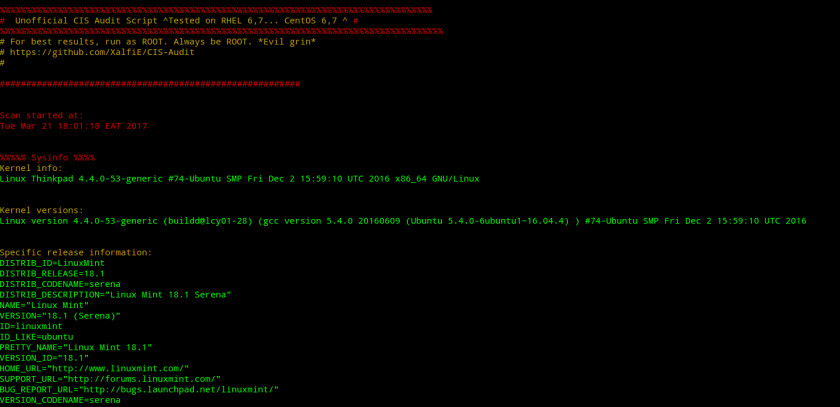
Пример вывода информации после запуска Nix Auditor
4. Loki — Simple IOC and Incident Response Scanner
Утилита Loki — не совсем классический инструмент для проведения аудита ИБ, однако отлично подходит для поиска следов взлома, что отчасти можно отнести и к практике аудита.

Логотип Loki Scanner
По заверениям разработчиков, вот такие возможности дает нам их тулза:
I. Четыре способа выявления взлома:
- имена файлов (соответствие регулярному выражению полного пути файла);
- проверка в соответствии с правилами Yara (поиск на соответствие сигнатурам Yara по содержимому файлов и памяти процессов);
- проверка хешей (сравнение просканированных файлов с хешами (MD5, SHA-1, SHA-256) известных вредоносных файлов);
- проверка обратной связи C2 (сравнивает конечные точки технологического соединения с C2 IOC).
II. Дополнительные проверки:
- проверка файловой системы Regin (через --reginfs);
- проверка аномалий системных и пользовательских процессов;
- сканирование распакованных SWF;
- проверка дампа SAM;
- проверка DoublePulsar — попытка выявить бэкдор DoublePulsar, слушающий порты 445/tcp и 3389/tcp.
Чуть-чуть коснемся того, как Loki определяет факт компрометации. Типовыми признаками (Indicators of Compromise), свидетельствующими, что компьютер был скомпрометирован (то есть взломан), могут быть:
- появление на компьютере malware (вирусов, бэкдоров, троянов, кейлоггеров, крипторов, майнеров и так далее), а также хакерских утилит (например, для исследования сети, эксплуатации уязвимостей, сбора учетных данных);
- появление неизвестных новых исполняемых и других файлов, даже если они не детектируются антивирусным движком как malware-код;
- аномальная сетевая активность (подключение к удаленным хостам, открытие для прослушивания портов неизвестными программами и прочее);
- аномальная активность на дисковых устройствах (I/O) и повышенное потребление ресурсов системы (CPU, RAM, Swap).
Перед началом инсталляции нужно доустановить несколько зависимых пакетов. Это colorama (дает расцветку строк в консоли), psutil (утилита проверки процессов) и, если еще не установлен, пакет Yara.
Итак, приступаем. Установка в Kali Linux (предварительно должен быть установлен пакет Yara, который по умолчанию уже инсталлирован в Kali Linux):
Установка в Ubuntu/Debian:
Установка в BlackArch:
Пример использования
Некоторые опции запуска:

Loki Scanner после первого запуска
Кстати, после установки утилиты неплохо бы проверить локальную базу IoC на обновления, сделать это можно с помощью команды Upgrader:
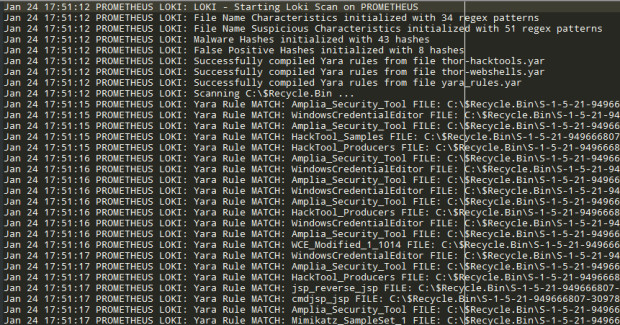
Пример ведения лога при сканировании
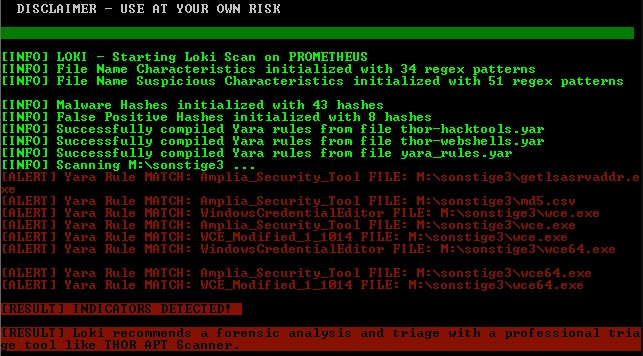
Информация об обнаруженных вредоносных файлах
5. Linux Security Auditing Tool (LSAT)
LSAT — заключительный в нашей подборке инструмент аудита безопасности Linux. Особенность данной тулзы в ее модульном дизайне, который, по заверениям разработчика, позволяет добавлять новые функции проверки очень оперативно. На сегодняшний момент в утилите заявлена поддержка всех самых распространенных ОС: Linux — Gentoo, Red Hat, Debian, Mandrake на архитектуре x86; SunOS (2.x), Red Hat, Mandrake на архитектуре Sparc; а также Apple macOS.
Либо для Debian/Ubuntu-дистрибутивов установить пакет можно прямо из репозитория:
Запускается утилита с помощью команды /lsat и добавленными опциями:
Заключение
Мы рассмотрели с тобой самые ходовые и в то же время очень крутые и функциональные тулзы для аудита безопасности Linux-серверов. Теперь ты сможешь хорошо подготовиться к сертификационному или какому-либо другому compliance-аудиту. Это также позволит тебе объективно оценить текущий уровень защищенности и в автоматическом или полуавтоматическом режиме оттюнинговать свою ферму Linux-машин на максимальный показатель hardening index!
Я же хочу рассказать, как создать кластеризацию на уровне приложений с высокой отказоустойчивостью в сжатые сроки, с ограниченным бюджетом и без глубоких познаний в построении кластеров. Оптимальным решением, на мой взгляд, будет использование Corosync и Pacemaker. Эта связка бесплатна, ее легко освоить, и на развертывание не уйдет много времени.
Corosync — программный продукт, который позволяет создавать единый кластер из нескольких аппаратных или виртуальных серверов. Corosync отслеживает и передает состояние всех участников (нод) в кластере.
Этот продукт позволяет:
Pacemaker — менеджер ресурсов кластера. Он позволяет использовать службы и объекты в рамках одного кластера из двух или более нод. Вот вкратце его достоинства:
Идея заключается в том, что с помощью Corosync мы построим кластер, а следить за его состоянием будем с помощью Pacemaker.
В теории
Попробуем решить следующие задачи.
- Развернуть кластер высокой отказоустойчивости из двух нод для обработки забросов от клиентов при условии, что они используют общий сетевой адрес и службу веб-сервера nginx.
- Протестировать отказ одной из нод в кластере, убедиться, что ресурсы передаются на рабочую ноду, когда активная нода упала.
- Время проверки сбоя на активной ноде 30 секунд.
Перед началом любых работ настоятельно советую нарисовать схему взаимодействия узлов сети. Это упростит понимание и принципы взаимодействия и работы узлов.
На практике
Настала пора реализовать намеченные задачи. Я в своем примере использовал дистрибутив Red Hat Enterprise Linux 7. Ты можешь взять любой другой Linux, принципы построения кластера будут те же.
Для начала установим пакеты, которые требуются для нормальной работы ПО на обеих нодах (ставим пакеты на обе ноды).
Следующую команду тоже нужно исполнять с правами рута, но если использовать sudo , то скрипт установщика отработает неверно и не создастся пользователь hacluster.
Проверяем пользователя hacluster (Pacemaker) и меняем пароль:
Авторизуемся на нодах под именем пользователя hacluster. Если выходит ошибка доступа к ноде ( Error: Unable to communicate with ha-node1 ), то, скорее всего, из-под Linux-УЗ наложены запреты на использование удаленных оболочек. Необходимо снять ограничение SUDO на время установки.
Когда увидишь следующее, можешь двигаться дальше:
User may run the following commands on ha-node1:
(ALL) NOPASSWD: ALL
Теперь проверяем на обеих нодах установленные пакеты corosync, pacemaker и pcs, добавляем в автозагрузку и запускаем службу конфигурации pacemaker.
Авторизуемся на нодах под пользователем hacluster:
Создаем кластер из двух нод:
Включаем и запускаем все кластеры на всех нодах:
При использовании двух нод включаем stonith. Он нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы. Игнорируем кворум.
Запрашиваем статус на обеих нодах ( $ sudo pcs status ) и видим:
2 nodes configured
0 resources configured
Online: [ ha-node1 ha-node2 ]
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Добавляем виртуальный сетевой адрес и nginx как ресурсы (надеюсь, ты помнишь про тайм-аут в 30 секунд) и запрашиваем статус кластера.
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started ha-node1
nginx (ocf::heartbeat:nginx): Started ha-node1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Выключаем первую ноду на несколько минут. Запрашиваем статус второй ноды, чтобы убедиться, что первая недоступна.
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started ha-node2
nginx (ocf::heartbeat:nginx): Started ha-node2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Как только первая нода будет доступна, вручную переключаем на нее виртуальный IP и nginx командой
Осталось запросить статус кластера и убедиться, что адрес присвоен первой ноде.
virtual_ip (ocf::heartbeat:IPaddr2): Started ha-node1
Список всех поддерживаемых сервисов можно посмотреть c помощью команды $ sudo crm_resource --list-agents ocf .
Кластеризация на базе nginx
На обеих нодах должен быть установлен и настроен nginx. Подключаемся к кластеру и создаем следующий ресурс:
Здесь мы создаем ресурс из службы, которая будет каждые 30 секунд проверяться, и в случае минутного тайм-аута ресурс будет включен на другой ноде.
Чтобы удалить ноду из кластера, воспользуйся командой $ sudo pcs cluster node remove <node_name> .
Выводы
Мы построили простой, но очень отказоустойчивый кластер для фронтенда приложения. Помни, что построение кластера — задача творческая и все зависит только от твоих смекалки и воображения. Невыполнимых задач для системного администратора не бывает!
Иван Рыжевцев
Системный администратор с богатым опытом. Прошедший огонь, воду и медные трубы. Главный девиз в жизни: Нерешаемых задач нет, надо только найти правильное решение!
В продолжение статьи «Кластерное хранилище Pacemaker + DRBD (Dual primary) + ctdb» представляю полностью готовый и рабочий вариант HA кластера файловой шары на 2-4 ноды для centos 6 и centos 7. Если вы хотите реализовать такое, вы либо извращенец, либо вам не дали никакого выбора, и реализовать надо хоть как-то.
Я просто опишу слоёный пирог, который мы будем собирать:
На блочном устройстве создаём таблицу gpt => один раздел на всё пространство под лвм => группу томов лвм на всё доступное пространство => лвм том на всё доступное пространство => drbd устройство => dlm => размечаем как физический том лвм на всё доступное пространство => на него кластерную группу томов лвм => лвм том на всё доступное пространство => размечаем фс gfs2 => подключаем в точку монтирования.
И рулить всем этим будет pacemaker c virtual ip адресом.

Если вы ещё хотите продолжать, читайте дальше под катом.
Процессор 1 ядро
1 Гб минимум оперативной памяти
15 Гб диск + место на котором вы будете хранить данные
Дисков может быть сколько угодно, даже один.
Если у вас один диск, то лучше размечать его следующим образом:
Таблица разделов gpt => раздел 200 Мб для efi (опционально) => раздел 1Гб для /boot => всё остальное место под лвм.
На лвм томе вам необходимо создать 2 группы томов. Первая группа томов под ОС размером 10 Гб + удвоенному размеру оперативной памяти, но не более 4 Гб.
Кто бы, что не говорил, но подкачка иногда очень выручает, поэтому на лвм группе создаём лвм раздел для подкачки равный удвоенному размеру оперативной памяти, но не более 4 Гб и оставшееся место отводим под корень ОС.
Вторая группа лвм под хранение данных. Создаём лвм раздел на всё оставшееся место.
По условиям нам дали 2 виртуальные машины и на этом всё. Ceph для корректной работы лучше ставить на 6 нодах, минимум 4, плюс было бы неплохо иметь какой-нибудь опыт работы с ним, а то получится как у cloudmouse. Gluster для сотен тысяч мелких файлов по производительности не пройдёт, это обмусолено на просторах хабра много раз. ipfs, lustre и тому подобные имеют такие же требования как у ceph или даже больше.
Начнём сражение! У меня было две виртуальные машины на CentOS 7 с 2мя дисками.
1) Pacemaker версии 1.1 не работает с ip корректно, поэтому для надёжности добавляем в /etc/hosts записи:
2) В стандартных репозиториях DRBD нет, поэтому надо подключить сторонний.
3) Устанавливаем drbd версии 8.4
4) Активируем и включаем в автозагрузку модуль ядра drbd
5) Создаём раздел диска и настраиваем лвм
6) Создаем конфигурационный файл ресурса drbd /etc/drbd.d/r0.res
7) Убираем сервис drbd из авозагрузки (позже его за него будет отвечать pacemaker), создаем метаданные для диска drbd, поднимаем ресурс
8) На первой ноде делаем ресурс первичным
9) Ставим pacemaker
10) Устанавливаем пароль для пользователя hacluster для авторизации на нодах
11) Запускаем pcsd на обоих нодах
12) Авторизуемся в кластере. C этого этапа делаем все на одной ноде
13) Создаем кластер с именем samba_cluster
14) активируем ноды и добавляем сервисы в автозагрузку и запускаем их
15) Так как в качестве серверов у нас выступают виртуальные машины, то отключаем механизм STONITH, так как мы не имеем никаких механизмов для управления ими. Так же у нас машин всего 2, поэтому кворум тоже отключаем, он работает только при 3х и более машинах.
17) Создаем ресурс drbd
18) Устанавливаем необходимые пакеты для clvm и подготавливаем clvm
19) Добавляем ресурс dlm и clvd в pacemaker
20) Запрещаем LVM писать кэш и очищаем его. На обоих нодах
21) Создаем CLVM раздел. Делаем только на одной ноде
22) Размечаем раздел в gfs2, здесь важно чтобы таблица блокировок имела тоже имя что и наш кластер в peacemaker. Делаем только на одной ноде
23) Дальше добавляем монтирование этого раздела в pacemaker и говорим ему грузиться после clvmd
24) Теперь наcтал черед ctdb, который будет запускать samba
25) Правим конфиг /etc/ctdb/ctdbd.conf
26) Создаем файл со списком нод /etc/ctdb/nodes
ВНИМАНИЕ! После каждого адреса в списке должен присутствовать перевод строки. Иначе нода не будет включаться при инициализации.
27) И наконец создаем ресурс ctdb
28) Задаем очередь загрузки и зависимости ресурсов для запуска
29) Задаем очередь остановки ресурсов, без этого ваша машина может зависнуть на моменте выключения
Сама шара может быть и на nfs, и на samba, но подключение к ним fail-over по IP, хотя само хранилище HA. Если вы хотите полный HA, то вместо samba и nfs вам надо ставить iSCSI и подключать через multipath. К тому же можно получить splitbrain в случае если одна из нод умрёт, а когда поднимется мастера не будет. Я проверил, что если ОС корректно выключается, то после поднятия ноды, когда мастера нет, она переходит в режим out-of-date и не становится мастером во избежание сплит брейна. Варианты с кворумом(DRBD и\или pacemaker) и любые извращения из каскадных конструкций DRBD после вашей настройки несостоятельны по причине высокой сложности, другой админ будет долго разбираться. Хотя с тем, что я написал не лучше, не делайте так.
Представьте ситуацию. Субботний вечер. Вы — администратор PostgreSQL, после тяжелой трудовой недели уехали на дачу за 200 км от любимой работы и чувствуете себя прекрасно… Пока Ваш покой не нарушает смс от системы мониторинга Zabbix. Произошел сбой на сервере СУБД, база данных с текущего момента недоступна. На решение проблемы отводится короткое время. И Вам ничего не остается, как с тяжелым сердцем оседлать служебный гироскутер и мчаться на работу. Увы!

А ведь могло быть по-другому. Вам приходит смс от системы мониторинга, что произошел сбой на одном из серверов. Но СУБД продолжает работать, поскольку отказоустойчивый кластер PostgreSQL отработал потерю одного узла и продолжает функционировать. Нет надобности срочно ехать на работу и восстанавливать сервер БД. Выяснение причин сбоя и работы по восстановлению спокойно переносятся на рабочий понедельник.
Как бы то ни было, стоит подумать о технологиях отказоустойчивы кластеров с СУБД PostgreSQL. Мы расскажем о построении отказоустойчивого кластера СУБД PostgreSQL с помощью программного обеспечения Pacemaker&Corosync.
Отказоустойчивый кластер СУБД PostgreSQL на основе Pacemaker
Сегодня в ИТ-системах уровня «business critical» спрос на широкую функциональность отходит на второй план. На первое место выходит спрос на надежность ИТ-систем. Для отказоустойчивости приходится вводить избыточность компонентов системы. Ими управляет специальное программное обеспечение.
Примером такого программного обеспечения является Pacemaker – решение компании ClusterLabs, позволяющее организовать отказоустойчивый кластер (ОУК). Работает Pacemaker под управлением широкого спектра операционных Unix-систем – RHEL, CentOS, Debian, Ubuntu.
Это программное обеспечение не создавали специально для работы с PostgreSQL или других СУБД. Сфера применения Pacemaker&Corosync значительно шире. Есть специализированные решения, заточенные под PostgreSQL, например multimaster, входящий в состав Postgres Pro Enterprise (компания Postgres Professional), или Patroni (компания Zalando). Но рассматриваемый в статье кластер PostgreSQL на основе Pacemaker/Corosync, достаточно популярен и подходит по соотношению простоты и надежности к стоимости владения для немалого числа ситуаций. Все зависит от конкретных задач. Сравнение решений не входит в задачи этой статьи.
Итак: Pacemaker — мозг и по совместительству менеджер ресурсов кластера. Его главная задача — достижение максимальной доступности ресурсов, которыми он управляет, и защита их от сбоев.
Во время работы кластера происходят различные события – сбой, присоединение узлов, ресурсов, переход узлов в сервисный режим и другие. Pacemaker реагирует на эти события в кластере, выполняя действия, на которые он запрограммирован., например, остановку ресурсов, перенос ресурсов и другие.
Для того, чтобы стало понятно, как устроен и работает Pacemaker, давайте рассмотрим, что у него внутри и из чего он состоит.
Итак, перейдем к сущностям Pacemaker.
Рисунок 1. Сущности pacemaker – узлы кластера
Первая и самая важная сущность – это узлы кластера. Узел (нода, node ) кластера представляет собой физический сервер или виртуальную машину с установленным Pacemaker.
Узлы, предназначенные для предоставления одинаковых сервисов, должны иметь одинаковую конфигурацию софта. То есть, если ресурс postgresql предполагается запускать на узлах node1, node2 , и он расположен в нестандартных путях установки, то на этих узлах должны быть одинаковые конфигурационные файлы, пути установки PostgreSQL, и конечно же, одинаковая версия PostgreSQL.
Следующая важная группа сущностей Pacemaker – ресурсы кластера. Вообще для Pacemaker ресурс — это скрипт, написанный на любом языке. Обычно эти скрипты пишутся на bash , но ничто не мешает писать их на Perl, Python, C или даже на PHP . Скрипт управляет сервисами в операционной системе. Главное требование к скриптам — уметь выполнять 3 действия: start, stop, monitor и делиться некоторой метаинформацией.
- IP адрес;
- сервис, запускаемый в операционной системе;
- блочное устройство
- файловая система;
- другие.
Атрибут priority — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут resource-stickiness — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут migration-threshold — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут failure-timeout — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
- block — установить опцию unmanaged, то есть деактивировать
- stop_only — остановить на всех узлах
- stop_start — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
Группы ресурсов
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс PostgreSQL, имеющий тип pgsql, и ресурс Virtual-IP, имеющий тип IPaddr2, могут быть объединены в группу.
Последовательность запуска в этой группе такая – сначала запускается PostgreSQL, и при его успешном запуске вслед за ним запускается ресурс Virtual-IP.
Кворум (quorum)
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже.
n > N/2, где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере.
Рисунок 2 – Отказоустойчивый кластер с кворумом
Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы.
Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
Архитектура Pacemaker
Архитектура Pacemaker представляет собой три уровня:

Рисунок 3 – Уровни Pacemaker
- Кластеронезависимый уровень – ресурсы и агенты. На этом уровне располагаются сами ресурсы и их скрипты. На рисунке обозначен зеленым цветом.
- Менеджер ресурсов (Pacemaker), это «мозг» кластера. Он реагирует на события, происходящие в кластере: отказ или присоединение узлов, ресурсов, переход узлов в сервисный режим и другие административные действия. На рисунке обозначен синим цветом.
- Информационный уровень (Corosync) — на этом уровне осуществляется сетевое взаимодействие узлов, т.е. передача сервисных команд (запуск/остановка ресурсов, узлов и т.д.), обмен информацией о полноте состава кластера ( quorum ) и т.д. На рисунке он обозначен красным.
Что нужно для работы Pacemaker?
- Синхронизация времени между узлами в кластере
- Разрешение имен узлов в кластере
- Стабильность сетевых подключений
- Наличие у узлов кластера функции управления питанием/перезагрузкой с помощью IPMI(ILO) для организации «фенсинга» (fencing – изоляция) узла.
- Разрешение прохождения трафика по протоколам и портам
Синхронизация времени – нужно, чтобы все узлы имели одно и то же время, обычно это реализуется установкой в локальной сети сервера времени ( ntpd ).
Разрешение имен – реализуется установкой в локальной сети сервера DNS. Если нет возможности установить сервер DNS, нужно на всех узлах кластера внести записи в файл /etc/hosts с именами хостов и IP-адресами.
Стабильность сетевых соединений. Необходимо избавиться от ложных срабатываний. Представьте, что у вас нестабильная локальная сеть, в которой каждые 5-10 секунд происходит потеря линка между узлами кластера и коммутатором. В таком случае, Pacemaker будет считать сбоем пропадание линка более, чем на 5 секунд. Пропал линк, ваши ресурсы «переехали». Потом линк восстановился. Но Pacemaker уже считает узел в кластере «сбойнувшим», он уже «перенес» ресурсы на другой узел. При следующем сбое, Pacemaker «перенесет» ресурсы на следующий узел, и так далее, пока не закончатся все узлы, и возникнет отказ в обслуживании. Таким образом, из-за ложных срабатываний весь кластер может перестать функционировать.
Наличие у узлов кластера функции управления питанием/перезагрузкой с помощью IPMI (ILO) для организации «фенсинга». Необходимо для того, чтобы при сбое узла изолировать его от остальных узлов. «Фенсинг» исключает ситуацию возникновения split-brain (когда появляются одновременно два узла, выполняющих роль Мастера СУБД PostgreSQL).
Разрешение прохождения трафика по протоколам и портам. Это важное требование, потому что в различных организациях службы безопасности часто устанавливают ограничения на прохождение трафика между подсетями или ограничения на уровне коммутаторов.
В таблице ниже приведен перечень протоколов и портов, которые необходимы для функционирования отказоустойчивого кластера.
Таблица 1 – Перечень протоколов и портов, необходимых для функционирования ОУК
В таблице приведены данные для случая отказоустойчивого кластера из 3-х узлов – node1, node2, node3 . Также подразумевается, что узлы кластера и интерфейсы управления питанием узлов (IPMI) находятся в разных подсетях.
Как видно из таблицы, необходимо обеспечить не только доступность соседних узлов в локальной сети, но и доступность узлов в сети IPMI.
Особенности использования виртуальных машин для ОУК
- fsync. Отказоустойчивость СУБД PostgreSQL очень сильно завязана на возможность синхронизировать запись в постоянное хранилище (диск) и корректное функционирование этого механизма. Разные гипервизоры по-разному реализуют кеширование дисковых операций, некоторые не обеспечивают своевременного сброса данных из кеша в систему хранения.
- realtime corosync. Процесс corosync в ОУК на основе Pacemaker отвечает за обнаружение сбоев узлов кластера. Для того, чтобы он корректно функционировал, нужно, чтобы ОС гарантированно планировала его исполнение на процессоре (ОС выделяет процессорное время). В связи с этим этот процесс имеет приоритет RT ( realtime ). В виртуализированной ОС нет возможности гарантировать такое планирование процессов, что приводит к ложным срабатываниям кластерного ПО.
- фенсинг. В виртуализированной среде механизм фенсинга ( fencing ) усложняется и становится многоуровневым: на первом уровне нужно реализовать выключение виртуальной машины через гипервизор, а на втором — выключение всего гипервизора (второй уровень срабатывает, когда на первом уровне фенсинга корректно не отработал). К сожалению, у некоторых гипервизоров нет возможности фенсинга. Рекомендуем не использовать виртуальные машины при построении ОУК.
Особенности использования PostgreSQL для ОУК
- Pacemaker при запуске кластера с PostgreSQL размещает файл блокировки LOCK.PSQL на узле с мастером СУБД. Обычно этот файл размещается в директории /var/lib/pgsql/tmp . Это делается с той целью, чтобы при сбое на Мастере запретить в дальнейшем автоматический запуск PostgreSQL. Таким образом, после сбоя на Мастере всегда требуется вмешательство администратора БД для устранения причин сбоя.
- Поскольку в ОУК используется стандартная схема PostgreSQL Master-Slave, то при определенных сбоях возможна ситуация возникновения двух Мастеров – т.н. split-brain. Например, сбой Потеря сетевой связности между каким-либо из узлов и остальными узлами (о всех видах сбоев см. далее). Во избежание этой ситуации необходимо выполнение двух важных условий при построении отказоустойчивых кластеров:
- наличие кворума в ОУК. Это означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
- Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку ( poweroff или hard-reset ).
Команды управления Pacemaker
- sudo pcs cluster auth node1 node2 node3 -u hacluster -p 'пароль‘
- Запуск кластера на всех узлах
- sudo pcs cluster start --all
- sudo pcs cluster start
- sudo pcs cluster stop
- sudo crm_mon -Afr
- sudo pcs resource cleanup
Мониторинг состояния кластера с помощью crm_mon
У Pacemaker есть встроенная утилита мониторинга состояния кластера. Системный администратор может с помощью нее видеть, что происходит в кластере, какие ресурсы на каких узлах расположены в настоящее время.
![]()
Рисунок 4 – Мониторинг состояния кластера с помощью команды crm_mon
pgsql-status
PRI – состояние мастера
HS:sync – синхронная реплика
HS:async – асинхронная реплика
HS:alone – реплика не может подключится к мастеру
STOP – PostgreSQL остановлен
pgsql-data-status
LATEST – состояние, присущее мастеру. Данный узел является мастером.
STREAMING:SYNC/ASYNC – показывает состояние репликации и тип репликации (SYNC/ASYNC)
DISCONNECT – реплика не может подключиться к мастеру. Обычно такое бывает, когда нет соединения от реплики к мастеру.
pgsql-master-baseline
Показывает линию времени. Линия времени меняется каждый раз после выполнения команды promote на узле-реплике. После этого СУБД начинает новый отсчет времени.Виды сбоев на узлах кластера
- Сбой по питанию на текущем мастере или на реплике. Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
- Сбой процесса PostgreSQL. Сбой основного процесса PostgreSQL – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
- Потеря сетевой связности между каким-либо из узлов и остальными узлами. Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
- Сбой процесса Pacemaker/Corosync. Сбой процесса Corosync/pacemaker аналогично сбою процесса PostgreSQL.
Виды планового обслуживания ОУК
- Выведение из эксплуатации Мастера или Реплики для плановых работ нужно в следующих случаях:
- замена вышедшего из строя оборудования (не приведшего к сбою);
- апгрейд оборудования;
- обновление софта;
- другие случаи.
Поскольку цель этой и так не короткой статьи – познакомить вас с одним из решений по отказоустойчивости СУБД PostgreSQL, вопросы установки, настройки и команды конфигурирования отказоустойчивого кластера не рассматриваются.
Автор статьи — Игорь Косенков, инженер Postgres Professional.
Рисунок — Наталья Лёвшина.Читайте также:
