
Добавить оглавление в djvu
Обновлено: 06.07.2024
Программа для добавление OCR информации в djvu-книги с помощью программы распознавания текста ABBYY FineReader версий 7-9. Есть также другие полезные функции для работы с djvu.
Текущая версия: 2.4 beta
FR9frfPatch для автоматического исправления перепутанных страниц после распознавания в FineReader 9 на многоядерном процессоре
Пожалуйста, если это возможно, то перешлите текст оглавления, который Вы показали на картинке на мой E-mail. Возможно Вы мой E-mail еще не выбросили в корзину.
Попытаюсь сделать bookmark.htm. К сожалению, с картинки я не могу скопировать текст.
Заранне спасибо.
А чем Вам мой вариант не нравится?
Из-за слишком жирных букв в OCR-слое очень много ошибок.
Процентов 20 троек превратилось в восьмерки, то же самое с пятерками - они стали шестерками.
Просто скопируйте текст оглавления и вставьте его в текстовый редактор - и вы сами все увидите.
Поэтому без предварительной (и очень тщательной) вычитки делать гиперссылки поверх TOC-оглавления (и страницы индексов) - imho - некорректно. Пользоваться результатом будет невозможно.
Bookmark-оглавление в данном случае применимо с большими оговорками - по той причине, что каждая строка в bookmark-оглавлении должна быть ссылкой на одну страницу, а данное оглавление - это немного по совместительству индекс, т.е. в нескольких случаях один и тот же элемент относится к разным диапазонам страниц.
Я все же действительно думаю, что в тех случаях, когда структура оглавления очень сложна и объем его велик, нагляднее будет вариант с разметкой оригинального оглавления на странице.
Другое дело, если Ваш метод позволит автоматически отфильтровать ошибки OCR. В общем, интересует, прежде всего наименее затратный по времени метод - книг много, а времени на них все меньше.
Получилось что-то типа
Кроме того перед запуском последовательности (после они уже не так выделялись) ручками прошелся по оглавлению, удалил остатки колонтитулов, объединил главы с текстом глав, а для третьей главы задал номер страницы, чтобы она могла иметь подглавы. Замечу, что в более простых случаях поиск колонтитулов можно было бы доверить Djvu Bookmarker, но не в вашем случае, потому что мы по сути заново создали разметку строк.
После запуска еще выделил все ссылки на страницы 3xx и сделал замену " 8" => " 3",
для пятисотых сделал замену " 6" => " 5" - против ошибок распознавания.
Затем текст выгрузил в Djvu Bookmarker, который по нарушению монотонности возрастания номеров страниц нашел остальные ошибки распознавания в номерах.
Кроме того, пришлось разлепить слипшиеся строки оглавления, в которых OCR не распознал длинный дефис - это вручную, задание на внимательность.
Потом закинул текст в иерархию, шаблоном CHAPTER автоматически создал структуру дерева. Вручную задвинул содержимое в подглавы третьей главы. И выдвинул индекс, попавший в последнюю главу.
Далее задал сдвиг нумерации по верхней строчке оглавления, проверил на последней - все сошлось, удаленных страниц не было.
Экспорт.
Все.
Vica3, я вообще не встречал просмотрщиков DJVU-файлов, да и самих файлов, с красивым оглавлением; сам формат создавался для хранения изначально "аналоговых" документов.
Обойтись традиционным оглавлением в начале/конце книжки.
К каждой странице документа (=изображению) присобачить слева краткое оглавление с гиперссылками. Что-то похожее есть на UniverTV: преподаватель читает лекцию, справа отображаются слайды, а снизу план занятия, щёлкая по пунктам которого можно перемещаться по видео
я встречала. но как это сделано - убей не пойму. Что-то не могу уяснить, что требуется, по описанию "надо красиво". Можно пример файла, оформленного "красиво" или просто скриншот глянуть? Jacky, будь это у меня под рукой - я бы его распотрошила:)
Красиво = с левой стороны, отдельно - интерактивное содержание. При прокрутке правой стороны содержание остается. где-то так.
Вариант К каждой странице документа (=изображению) присобачить слева краткое оглавление с гиперссылками. мне не понравился, т.к. страниц более 400:(
Хм. Ладно, спрошу по-другому. Вот это оно или нет?
Именно пример, приведенный там, я для наглядности и внедрил в первый попавшийся djvu-документ, т.ч. можно сразу увидеть на скриншоте, как будет выглядеть такая структура.
Нужный файл оглавления можно сгенерировать с помощью Adobe Acrobat, если есть исходник pdf, который перегоняется в djvu. Если такового нет, то файл можно сделать вручную. У него простая структура, достаточно только выдерживать вложенность тегов ul и li. Писать и сохранять лучше в текстовом редакторе, позволяющем явно указать кодировку utf-8 для текста, например Akelpad.
Нужный файл оглавления можно сгенерировать с помощью Adobe Acrobat, если есть исходник pdf, который перегоняется в djvu.
Jacky, я к вечеру ближе торможу - как это сделать (сгенерировать файл оглавления в АА в исходнике пдф)? Или сначала из пдф в хтмл?
Во всяком случае это тот путь, который мне известен. В принципе оно не так страшно, как кажется, если у вас не слишком разветвленное оглавление с сотнями разделов и подпунктов в каждой главе.
Впрочем, если кто-то уточнит, как генерировать оглавление уже с нужными якорями, не откажусь узнать рецепт.
А вообще в последнее время как-то прохладно стал относиться к формату djvu. Нет, конечно выигрыш в объеме файла может быть существенный и еще ряд нюансов, но в общем и целом pdf как-то комфортнее, что ли. Тем более, что книги в djvu ради снижения объема зачастую доводят до совершенно непристойного качества картинки. В наше время, с распространением всё более ёмких носителей информации и широкополосного интернета все эти ухищрения постепенно теряют смысл.
- ЖАНРЫ 360
- АВТОРЫ 278 525
- КНИГИ 658 004
- СЕРИИ 25 236
- ПОЛЬЗОВАТЕЛИ 614 349
Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро
Итак: перед вами взятая у приятеля, из библиотеки, или просто хорошая, интересная книга, которую хотелось бы иметь на компьютере. И не просто иметь, а иметь в таком виде, который позволил бы выполнять поиск по тексту, удобно читать книгу на экране монитора или на устройствах еВоок, а если это не научно-техническая или справочная литература – еще и читать на любимом сотовом телефоне, iPhon'e или PDA. В этом пошаговом руководстве, основанном на собственном опыте, я постараюсь рассказать о том, как «выжать» максимум результатов из проделанной простой, но иногда весьма утомительной работы по сканированию книги.
Пусть вас не испугает длина этого руководства и кажущаяся сложность сканирования и обработки книги. Процесс действительно довольно сложен и многоступенчат, но поверьте мне, описать все эти операции было гораздо труднее, чем выполнить их шаг за шагом.
Шаг 1. Сканирование
1.1 Подготовка к процессу
Сканирование, с которого начинается, зачастую, долгий путь «в Сеть» любой изданной когда-либо книги (рынок легальных электронных книг, размещаемых издателями непосредственно после электронной верстки, у нас совершенно неразвит) – это самая монотонная часть всей предстоящей работы, поэтому к ней стоит тщательно подготовиться заранее – протереть стекло сканера, проверить наличие свободного места на диске – несжатый скан одной средней по размеру книги может занимать до 1 Гбайт. Потом начинается собственно сканирование.
Я намеренно не привожу здесь сравнительных характеристик разных моделей сканеров, поскольку каждый из нас в подавляющем большинстве случаев располагает только одним сканером, характеристики которого более или менее хорошо известны.
Phistek OpticBook: преимущества и недостатки

Из всех сканеров, имеющихся на рынке, для сканирования книг в больших количествах нет ничего лучше серии Plustek OpticBook. Эти планшетные сканеры отличаются высоким корпусом и прозрачным основанием, выполненным "в край" – так, чтобы на него можно было уложить книгу, не ломая и не деформируя корешок. Такой сканер – идеален для перевода в электронный вид десятков томов, например из библиотеки университетской кафедры. Однако, для домашнего повседневного применения он практически непригоден. Причина этого – в сугубой спецbализированности устройства под книгосканирование и OCR. В конструкции PlusTek OpticBook в жертву быстродействию и разрешению принесено все, что только можно, включая четкость, избирательность и цветопередачу.
Сканирование всех своих книг я проводил и провожу на достаточно старом (2003 года выпуска) полупрофессиональном планшетном сканере для документсистем Hewlett-Packard ScanJet 6390с. Эта машина отличается высоким быстродействием (15-25 сек на страницу формата А4 в режиме градаций серого). Кроме того, в ее комплект поставки входит удобное программное обеспечение HP Precision Scan Pro. Именно на этой программе сделаны все скрины с примерами сканирования.
Заранее хочу предостеречь от использования в качестве основного инструмента сканирования программы FineReader. Оставим эту программу до стадии OCR. Пока она может лишь максимально усложнить нам задачу пакетной обработки, применив (причем, без нашего ведома) – свои не слишком хорошие алгоритмы чистки и сжатия сканов. А главное – она практически лишит нас шансов применить важнейший прием – оверсемплинг до разрешения 600 dpi.
Собственно сканирование состоит из трех этапов: сканирования обложки, основной части книги, цветных вклеек и иллюстрации. Последовательно описывать эти этапы нет смысла – они переплетаются друг с другом в зависимости от верстки книги. Стоит привести лишь параметры сканирования, оптимальные для разных типов книжных страниц.
Здесь приведу еще одно важнейшее предупреждение(!):
На некоторых очень старых моделях сканеров есть возможность вручную включать внутренний оверсемплинг, тo есть фактически сканировать с меньшим разрешением, чем имеет выходной файл. Обозначается такая установка разрешения обычно словом Software или Resampled. Эту установку использовать нельзя! Ее включение приведет в полную негодность полученные файлы, и их дальнейшая обработка окончательно потеряет смысл. Также нельзя использовать установку сканирования в режиме Linearеt или Black amp;White (одноцветный)
Общие рекомендации такие: для текстовых страниц используйте:
• Режим Grayscale (оттенки серого), для цветных иллюстраций и обложек – True Color (полноцветный).
• Разрешение сканирования – 300 dpi (только оптическое, повторимся еще раз!).
• Остальные установки можно оставить по умолчанию.
Таблица 1. Оптимальные параметры сканирования
Эти параметры не являются догмой. Они определены опытным путем на нескольких моделях неспециализированных сканеров, и служат ориентировочным целям. Собственный набор оптимальных параметров книгосканирования всегда стоит определить экспериментально, отсканировав любимую книгу со всеми иллюстрациями и обложкой. Приводя эти параметры, я стремился обобщить их для применения на максимальном количестве моделей сканеров.
Разрешение: 300 dpi
Резкость: Low или Medium
Яркость и контраст: Любые, специальные параметры не использовать
Разрешение: 300 dpi
Резкость: Medium. High
Яркость и контраст: Любые, можно применить пресет B amp;W Photo
Разрешение: 300 dpi
Резкость: High можно применить пресет B amp;W Photo
Яркость и контраст: Определяются по предварительному сканированию
Режим: True Color
Разрешение: 300 dpi
Резкость: Low, можно применить пресет Photo
Яркость и контраст: Определяются по предварительному сканированию
Тип страницы: Цветная обложка или иллюстрация страничного формата
Режим: True Color
Разрешение: 300 dpi
Резкость: Low, можно применить пресет Photo
Яркость и контраст: Определяются по предварительному сканированию
Формат выходного файла: Uncompressed (Несжатый) TIFF(!)
Почему не JPEG?
Формат JPEG для сохранения сканов книжных страниц использовать можно, но не нужно.
Во-первых: потому, что этот формат даже при включенном сжатии без потерь (Quality = 100) оставляет артефакты в виде «квадратиков».
Во-вторых и самых главных: многократное пережатие при сохранении обработанного файла JPEG вновь в «свой» формат за 2-3 цикла обработки приводит изображение в негодность.
Отдельно коснемся использования сжатого (Compressed) TIFF: при сохранении сжатого изображения в TIFF можно использовать алгоритмы сжатия: ZIP. LZW (без потерь). JPEG (с потерями). Без хлопот программы распознавания вроде FineReader понимают только JPEG.
Со всеми остальными форматами проблемы могут возникать непредсказуемо (например, у меня FineReader 7.0 испытывает устойчивую «идиосинкразию» конкретно к формату сжатия LZW). Поэтому если нет особых проблем с наличием места на диске, лучше всегда использовать несжатый файл.
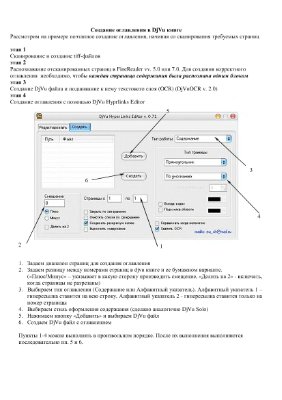
Программа для автоматического создания гиперссылочного оглавления (и/или алфавитного указателя) в многостраничных DjVu-файлах (т. е. DjVu-книгах).
Принцип действия:
1. Программа работает только с такими DjVu-книгами, которые содержат внедрённый текстовый OCR-слой (желательно программой DjVu OCR 2.1).
2. Пользователь указывает программе местонахождение страниц DjVu-книги, содержащих сканированное изображение содержания (или оглавления) исходной бумажной книги, а также вводит мелкие опции.
3. Затем программа полностью автоматически делает следующее:
А. Считывает внедрённый текстовый OCR-слой из указанных страниц "оглавления" DjVu-книги.
Б. Анализирует эту информацию, генерирует на её основе гиперссылки.
В. Вставляет эти гиперссылки в данные страницы "оглавления" DjVu-книги.
В результате получается навигационный механизм для работы с DjVu-книгой - на страницах со сканированными изображениями оглавления исходной бумажной книги появляются гиперссылки для перехода на соответствующие страницы DjVu-книги. Тем самым также достигается наибольшее приближение к использованию оглавления исходной бумажной книги.
DjVu Document Express Editor 6.0 Pro+Rus
- формат txt, exe
- размер 53.25 МБ
- добавлен 16 июня 2009 г.
Разработчик: LizardTech, Inc. Статус программы: Shareware Интерфейс: Русский Размер файла: 54 Mb Версия: 6.01 Система: Windows 95/98/Me/NT/2000/XP/Vista Формат: DjVu, BMP, GIF, JPEG, PNM, TIFF, PICT DjVu Document Express Editor Pro 6.0.1 – Одна из наиболее распространенных и корректно работающих программ для создания и просмотра DjVu-документов от правопреемника самого стандарта DjVu компании LizardTech – Document Express Editor. В Document Exp.
DjVu Document Express Editor 6.0.1.1320 Rus (Portable)
- формат exe
- размер 11.09 МБ
- добавлен 29 сентября 2009 г.
Программа для создания, редактирования, и чтения документов формата DjVu. В эту сборку включили модули OCR - оптического распознавания текста для русского и английского языков. В архиве портативная русская версия. Сборка - irokkezz. Год: 2009 Версия: 6.0.1.1320 Разработчик: Платформа: Win All Язык интерфейса: Русский + Английский Размер: 11.09 Мбrn
DjVu Document Express Editor Pro 6.0.1 build 1320
- формат txt, exe
- размер 53.26 МБ
- добавлен 22 ноября 2009 г.
Одна из наиболее распространенных и корректно работающих программ для создания и просмотра DjVu-документов от правопреемника самого стандарта DjVu компании LizardTech — Document Express Editor. В Document Express Editor, можно открывать и конвертировать файлы следующих форматов: DjVu (*.djvu, *.djv), BMP (*.bmp), GIF (*.jpg), JPEG (*.jpg, *.jpg), PNM (*.pnm, *.ppm, *.pgm, *.pbm), TIFF (*.tiff, *.tif), PICT (*.pict). При сохранении файла программ.
DjVu Document Express Editor Pro 6.0.1.1320
- формат txt
- размер 1.41 МБ
- добавлен 29 марта 2009 г.
Мощная программа для просмотра, создания и редактирования (! ) .djvu и .djv файлов. Сначала ставим программу, затем - русификатор. Свободная версия.rn
DjVu Editor 4.1 Pro Rus build 333
- формат exe
- размер 2.44 МБ
- добавлен 27 февраля 2009 г.
Программа для просмотра, редактирования и создания книг в формате djvu. С её помощью можно легко создать книгу из картинок и разобрать назад на картинки. Функции программы: 1. Просматривает файлы электронных книг (ebook: DjVu) 2. Есть настройки отображения книги 3. Простой, интуитивно понятный интерфейс. 4. Имеет функцию сканирования. 5. Поддерживает несколько форматов, таких как: DjVu, IW44, BMP, JPEG, GIF, TIFF, PMP, PICT 6. Очень маленький ра.
DjVu Reader 2.0.0.26 + DjVu Editor Pro v. 4.1.0+DjVu Plug-in 6.1.0
- формат exe, txt, html
- размер 9.65 МБ
- добавлен 30 марта 2010 г.
Программное обеспечение для работы с документами формата djvu. В программе djvu reader ведется история файлов, поэтому на открытие последних десяти документов у вас будет уходить значительно меньше времени. DjVu Plug-in 6.1.0: Приложение djvu reader поддерживает словари и для перевода слова вам необходимо лишь навести курсор мыши на выбранный фрагмент.rn
DjVu Small v0.4.4
- формат txt, htm, html, exe, jar, gif, jpg
- размер 1.46 МБ
- добавлен 24 мая 2011 г.
Программа для создания DjVu-файлов (из обычных графических файлов в форматах BMP, TIF, JPG, GIF и PNM) и для декодирования DjVu-файлов (в обычные графические файлы) - в операционных системах Windows 98 / NT / XP. DjVu Small поддерживает кодирование в DjVu как множества обычных графических файлов (получается многостраничный DjVu-файл), так и одиночных графических файлов (получается одностраничный DjVu-файл). Также программа умеет декодировать люб.
DjVuToy 1.0.1
- формат exe
- размер 868.14 КБ
- добавлен 10 июня 2011 г.
Многооперационный инструментарий для работы с DJVU-файлами (Friendware). Merger. Splitter. Page Editor. Index File. Bookmark. DPI & Width. To Image. Hidden Text. To PDF. File Info.rn
DjVuToy 1.14
- формат exe
- размер 2.37 МБ
- добавлен 03 июня 2011 г.
Многооперационный инструментарий для работы с DJVU-файлами (Friendware). Merger. Splitter. Page Editor. Index File. Bookmark. DPI & Width. To Image. Hidden Text. To PDF. File Info.rn
Document Express Editor 6.0.1 Bild 1320
- формат exe
- размер 1.16 МБ
- добавлен 03 февраля 2012 г.
Редактор для djvu. В отличие от DJVU Solo 3.1 расспознаёт более новые форматы (фирма LizardTech перестала поддерживать своё детище). Можно сохранять любой лист из журнала ,а затем собрать их в отдельный файл djvu. Очень удобно при создании своих сборок по определённой тематики.rn
Читайте также: