
Как посмотреть файл robots txt у сайта
Обновлено: 02.07.2024
Файл robots.txt необходим для правильного сканирования и индексирования сайта роботами поисковых систем. Отсутствие файла или ошибки в нём могут негативно повлиять на ранжирование как отдельных веб-страниц, так и всего сайта.
Содержание
Видео по теме
Для чего нужен файл robots.txt?
Robots.txt позволяет запретить роботам сканировать определенные страницы, директории и отдельные файлы сайта.
Простейший пример содержания robots.txt, которое равнозначно отсутствию самого файла:
В то же время следующий код означает противоположный результат:
Управление сканированием
Robots.txt позволяет упорядочить процесс сканирования страниц и файлов сайта, что способствует:
- снижению нагрузки на сервер,
- ускорению попадания нужных страниц в поисковую выдачу,
- исключению попадания ненужных страниц в поисковую выдачу,
- индексированию главного зеркала сайта.
Управление индексированием
Запрет на сканирование в robots.txt не гарантирует исключение данных страниц из поисковой выдачи (индексной базы), т. к. правила в файле носят рекомендательный характер:

Настройки файла robots.txt являются указаниями, а не прямыми командами. Googlebot и большинство других поисковых роботов следуют инструкциям robots.txt, однако некоторые системы могут игнорировать их.
Справка Google
Кроме того, инструкции в robots.txt не могут отменить входящие с внешних ресурсов ссылки, благодаря которым поисковые роботы могут попасть на те страницы сайта, которые формально запрещены для сканирования в файле:
Нельзя использовать файл robots.txt, чтобы скрыть страницу из результатов Google Поиска. На нее могут ссылаться другие страницы, и она все равно будет проиндексирована.
Справка Google
Для того, чтобы запретить поисковым роботам индексировать страницы, следует применять мета-тег Robots. Однако это не касается изображений:
Файл robots.txt может использоваться для скрытия изображений из результатов поиска. Однако они будут доступны посетителям, и их все ещё можно будет открыть с других страниц.
Справка Google
Таким образом, robots.txt позволяет управлять сканированием сайта и индексированием изображений, но не исключает индексирование прочих файлов.
Как создать файл robots.txt?
При создании необходимо соблюдать ряд общих требований поисковых систем к данному файлу для того, чтобы поисковые роботы могли следовать его инструкциям.
Требования к файлу
У всех поисковых систем есть общие требования к robots.txt, которые необходимо учитывать при его создании:
- файл должен быть в формате txt ,
- файл должен называться robots (в нижнем регистре),
- файл должен быть доступен по URL-адресу домен/robots.txt ,
- при запросе файла сервер должен возвращать код 200 OK,
- размер файла не должен превышать 500 Кб.
При несоблюдении первых трех требований поисковые роботы просто не смогут найти файл из-за несоответствия формата/названия/URL-адреса файла правилам, установленным стандартом. Последние два пункта актуальны для роботов Яндекса:

Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс.Помощь
Правильный robots.txt
Соблюдение вышеперечисленных требований позволяет обеспечить доступ к файлу поисковым роботам. Чтобы создать правильный robots.txt, необходимо хорошо изучить его синтаксис. В зависимости от сложности структуры сайта и его системы управления неправильно созданный файл может затруднить его сканирование и индексирование, а также способствовать увеличению нагрузки на сервер.
Процесс cоздания файла
Чтобы правильно сделать robots.txt для вашего сайта, следуйте следующему алгоритму действий:
- создайте простой текстовый файл формата txt ,
- переименуйте его в robots,
- внимательно изучите синтаксис стандарта,
- откройте созданный файл с помощью блокнота (или другого текстового редактора), файл (заполните с учетом особенностей сайта),
- осуществите проверку файла,
- при отсутствии ошибок, скопируйте созданный файл в корневую директорию сайта,
- проверьте его доступность по URL-адресу домен/robots.txt.
Генератор robots.txt
Синтаксис и директивы стандарта
Стандарт robots.txt отличается оригинальным синтаксисом. Существуют общие для всех роботов директивы (правила), а также директивы, понятные только роботам определенных поисковых систем.
Комментарии
Стандартные директивы
Директивами для robots.txt называются правила, состоящие из названия и значения (параметра), идущего после знака двоеточия. Например:
Регистр символов в названиях директив не учитывается.
Для большинства директив стандарта в качестве значения применяется URL-префикс (часть URL-адреса). Например:
Регистр символов учитывается роботами при обработке URL-префиксов.
Директива User-agent
Правило User-agent указывает, для каких роботов составлены следующие под ним инструкции.
Значения User-agent
В качестве значения директивы User-agent указывается конкретный тип робота или символ * . Например:
Основные типы роботов, указываемые в User-agent :
Yandex Подразумевает всех роботов Яндекса. YandexBot Основной индексирующий робот Яндекса YandexImages Робот Яндекса, индексирующий изображения. YandexMedia Робот Яндекса, индексирующий видео и другие мультимедийные данные. Google Подразумевает всех роботов Google. Googlebot Основной индексирующий робот Google. Googlebot-Image Робот Google, индексирующий изображения.
Регистр символов в значениях директивы User-agent не учитывается.
Обработка User-agent
Чтобы указать, что нижеперечисленные инструкции составлены для всех типов роботов, в качестве значения директивы User-agent применяется символ * (звездочка). Например:
Перед каждым последующим набором правил для определённых роботов, которые начинаются с директивы User-agent , следует вставлять пустую строку.
При этом нельзя допускать наличия пустых строк между инструкциями для конкретных роботов, идущими после User-agent :
Обязательно следует помнить, что при указании инструкций для конкретного робота, остальные инструкции будут им игнорироваться:
Директива Disallow
Правило Disallow применяется для составления исключающих инструкций (запретов) для роботов. В качестве значения директивы указывается URL-префикс. Первый символ / (косая черта) задает начало относительного URL-адреса. Например:
Применение директивы Disallow без значения равносильно отсутствию правила:
Директива Allow
Правило Allow разрешает доступ и применяется для добавления исключений по отношению к правилам Disallow . Например:
При равных значениях приоритет имеет директива Allow:
Директива Sitemap
В качестве значения директивы Sitemap в указывается прямой (с указанием протокола) URL-адрес карты сайта:
Директива Sitemap является межсекционной и может размещаться в любом месте robots.txt. Удобнее всего размещать её в конце файла, отделяя пустой строкой.
Следует учитывать, что robots.txt является общедоступным, и благодаря директиве Sitemap злоумышленники могут получить доступ к новым страницам раньше поисковых роботов, что может повлечь за собой воровство контента.
Регулярные выражения
В robots.txt могут применяться специальные регулярные выражения в URL-префиксах с помощью символов * и $ .
Символ /
Символ / (косая черта) является разделителем URL-префиксов, отражая степень вложенности страниц. Важно понимать, что URL-префикс с символом / на конце и аналогичный префикс, но без косой черты, поисковые роботы могут воспринимать как разные страницы:
Символ *
Символ * (звездочка) предполагает любую последовательность символов. Он неявно приписывается к концу каждого URL-префикса директив Disallow и Allow :
Символ * может применяться в любом месте URL-префикса:
Символ $
Символ $ (знак доллара) применяется для отмены неявного символа * в окончаниях URL-префиксов:
Символ $ (доллар) не отменяет явный символ * в окончаниях URL-префиксов:
Директивы Яндекса
Роботы Яндекса способны понимать три специальных директивы:
- Host (устарела),
- Crawl-delay,
- Clean-param.
Директива Host
Директива Host является устаревшей и в настоящее время не учитывается. Вместо неё необходимо настраивать редирект на страницы главного зеркала.
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы на загрузку, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Яндекс.Помощь
Правило Crawl-delay следует размещать в группу правил, которая начинается с директивы User-Agent , но после стандартных для всех роботов директив Disallow и Allow :
В качестве значений Crawl-delay могут использоваться дробные числа:
Директива Clean-param
Директива Clean-param помогает роботу Яндекса верно определить страницу для индексации, URL-адрес которой может содержать различные параметры, не влияющие на смысловое содержание страницы.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Яндекс.Помощь
В качестве значения правила Clean-param указывается параметр и URL-префикс адресов, для которых не следует учитывать данный параметр. Параметр и URL-префикс должны быть разделены пробелом:
Для указания 2-х и более незначительных параметров в одном правиле Clean-param применяется символ & :
Директива Clean-param может быть указана в любом месте robots.txt. Все указанные правила Clean-param будут учтены роботом Яндекса:
Настройка файла robots.txt
Правильная настройка файла позволит избежать ошибок при индексировании сайта, а также поможет поисковым роботам правильно его сканировать.
Как правильно настроить robots.txt?
Большинство сайтов, в зависимости от используемой CMS, имеет ряд страниц с одинаковым контентом, содержащих различные параметры в URL-адресах. Кроме того, содержание страниц по одинаковым URL-адресам иногда может меняться в зависимости от определённых условий. Такие страницы необходимо оградить от индексирования и сканирования. Чтобы облегчить работу поисковым роботам в отношении вашего сайта, нужно грамотно ограничить доступ к следующим страницам:
Как запретить индексацию в robots.txt?
На примерах разберем настройку запретов индексации.
Как закрыть сайт от индексации?
Чтобы запретить индексацию всего сайта применяется следующая настройка:
Как запретить индексацию страницы?
Чтобы запретить индексацию конкретной страницы нужно настроить файл следующим образом:
Как запретить индексацию папки?
Чтобы запретить индексацию папки с вложенными директориями и файлами применяются следующие настройки:
Запрет индексации каталога вместе с исходной страницей:
Как запретить индексацию страниц с параметрами?
Запрет индексации страниц с определёнными расширениями
Чтобы запретить индексацию всех страниц с конкретными расширениями, правила применяются в следующем виде:
Как разрешить индексацию в robots.txt?
Следующие условия означают, что сайт открыт для индексации и сканирования:
- если файл отсутствует или он пустой,
- если применяются указанные ниже настройки.
Разрешать индексирование отдельных файлов и папок приходится в исключительных случаях, когда родительская папка настроена на запрет:
Как указать Sitemap в robots.txt?
Чтобы добавить Sitemap (сообщить поисковым роботам о существовании файла карты сайта) применяется директива Sitemap :
Важное примечание
В качестве завершения напомним, что настройка запретов индексации в robots.txt не гарантируют непопадание данных страниц и каталогов в индекс, т. к. роботы могут попадать на закрытые в файле страницы по ссылкам с других ресурсов. Для того, чтобы полностью исключить возможность индексирования страниц и каталогов, следует использовать дополнительные настройки (например, мета-тег Robots ).
Как проверить файл robots.txt?
Для проверки на правильность можно воспользоваться специальными инструментами-анализаторами, которые нам любезно предоставляют ведущие поисковые системы рунета.
Анализ robots.txt онлайн в Яндекс
Проверить правильность файла можно с помощью инструмента сервиса Яндекс.Вебмастер. Авторизация не обязательна.
Преимущества анализатора Яндекса
Можно скопировать текст файла, не указывая ссылку на него. Это удобно, когда файл еще не размещен в интернете.
Если файл уже размещен в интернете, для проверки достаточно указать URL сайта.
Позволяет проверять доступность URL-адресов для роботов, в т. ч. относительных, если проверяемый сайт не указан.
Единственным значимым недостатком анализатора от Яндекса является необходимость авторизации.
Как проверить файл в Яндексе?
Проверять robots.txt в инструменте от Яндекса можно с указанием URL-адреса сайта, или просто введя код файла в текстовую область для проверки.
Проверка не размещённого в интернете файла
Рассмотрим процесс проверки robots.txt с помощью инструмента от ПС Яндекс без указания URL-адреса сайта:
Проверка файла для определённого сайта
Чтобы проверить размещённый в интернете для конкретного сайта robots.txt с помощью анализатора Яндекса, перейдём к вышеописанному пункту 2 и, вместо ввода кода в текстовую область, указываем доменное имя проверяемого сайта в соответствующее текстовое поле и жмем стрелочку напротив него:

После этого в тестовой области «Текст robots.txt» отобразится код файла для указанного сайта. Далее следует действовать, как описано выше.
Проверка доступности URL-адресов для роботов
С помощью анализатора можно проверить, какие URL-адреса попадают под запрет.
Анализ robots.txt онлайн в Google
Инструмент проверки правильности файлов robots.txt от Google менее удобен, т. к. требуется авторизация в сервисе Search Console и сайт, подтверждённый в данном сервисе.
Преимущества анализатора от Google
После добавления сайта файл проверяется автоматически. Отчет появляется на странице анализатора.
Нельзя вносить изменения в robots.txt, размещённый на сервере, но можно вносить правки в редакторе, скачивать файл и заменять его на сервере.
После обновления файла можно сообщить Google об этом.
Позволяет проверять доступность URL-адресов для роботов с возможностью выбора типа робота.
Недостатки анализатора от Google
Необходима регистрация в сервисе Google Search Console.
Нельзя проверить код, просто скопировав его, или загрузив файл с локального компьютера.
Нельзя проверить файл для сайта, не подтверждённого в Search Console.
Как проверить robots.txt в Google?
Рассмотрим процесс проверки файла в Search Console.
Проверка файла для определённого сайта
Требуется авторизация в поисковой системе Google. Если у Вас нет аккаунта, то необходимо его создать.
Выберите сайт, для которого Вы желаете проверить robots.txt. Если сайта нет – необходимо пройти процедуру добавления сайта.
Развернутся дополнительные элементы навигации.
Вы попадете на страницу соответствующего инструмента. Если для текущего сайта существует robots.txt, размещённый в корне сайта, то на странице будут отображаться:
- дата последней проверки файла,
- статус ответа сервера при запросе файла,
- размер файла,
- содержимое файла,
- ошибки и предупреждения.
Проверка доступности URL-адресов
- в нижней части страницы инструмента введите относительный URL страницы для проверки,
- выберите тип робота Google, от лица которого будет проводиться проверка,
- кликните Проверить ,
- статус отобразиться на месте кнопки Проверить .



Дополнительные возможности
-
Скачайте обновленный код.
Клик по соответствующей кнопке осуществит скачивание файла с кодом, который отображался в редакторе. Эта возможность позволяет осуществить правильную настройку robots.txt непосредственно в анализаторе Google, после чего скачать готовый файл и заменить его на сервере.
Клик по соответствующей кнопке осуществит переход к robots.txt текущего сайта. Позволяет проверить наличие файла на сайте.
Клик по соответствующей кнопке позволяет сообщить Google о том, что файл обновлен, и роботам следует обратить внимание на новые правила.
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
- Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
Советы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots.txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
Выберите в левом меню раздел Инструменты → Анализ robots.txt.Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:


Чтобы сделать проверку с помощью Google:

Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.

Проверка robots.txt Google не выявила ошибок
В интернете каждый день появляются готовые решения по той или иной проблеме. Нет денег на дизайнера? Используйте один из тысяч бесплатных шаблонов. Не хотите нанимать сео-специалиста? Воспользуйтесь услугами какого-нибудь известного бесплатного сервиса, почитайте сами пару статей.
Уже давно нет необходимости самому с нуля писать тот же самый robots.txt. К слову, это специальный файл, который есть практически на любом сайте, и в нем содержатся указания для поисковых роботов. Синтаксис команд очень простой, но все равно на составление собственного файла уйдет время. Лучше посмотреть у другого сайта. Тут есть несколько оговорок:
Сайт должен быть на том же движке, что и ваш. В принципе, сегодня в интернете куча сервисов, где можно узнать название cms практически любого веб-ресурса.
Это должен быть более менее успешный сайт, у которого все в порядке с поисковым трафиком. Это говорит о том, что robots.txt составлен нормально.

Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Итак, чтобы посмотреть этот файл нужно в адресной строке набрать: доменное-имя.зона/robots.txt
Все неверятно просто, правда? Если адрес не будет найден, значит такого файла на сайте нет, либо к нему закрыт доступ. Но в большинстве случаев вы увидите перед собой содержимое файла:

В принципе, даже человек не особо разбирающийся в коде быстро поймет, что тут написать. Команда allow разрешает что-либо индексировать, а disallow – запрещает. User-agent – это указание поисковых роботов, к которым обращены инструкции. Это необходимо в том случае, когда нужно указать команды для отдельного поисковика.
Что делать дальше?
Скопировать все и изменить под свой сайт. Как изменять? Я уже говорил, что движки сайтов должны совпадать, иначе изменять что-либо бессмысленно – нужно переписывать абсолютно все.
Итак, вам необходимо будет пройтись по строкам и определить, какие разделы из указанных присутствуют на вашем сайте, а какие – нет. На скриншоте выше вы видите пример robots.txt для wordpress сайта, причем в отдельном каталоге есть форум. Вывод? Если у вас нет форума, все эти строки нужно удалить, так как подобных разделов и страниц у вас просто не существует, зачем тогда их закрывать?
Самый простой robots.txt может выглядеть так:
Практический курс по верстке адаптивного сайта с нуля!
Изучите курс и узнайте, как верстать современные сайты на HTML5 и CSS3
Все вы наверняка знаете стандартную структуру папок в wordpress, если хотя бы 1 раз устанавливали этот движок. Это папки wp-admin, wp-content и wp-includes. Обычно все 3 закрывают от индексации, потому что они содержат чисто технические файлы, необходимые для работы движка, плагинов и шаблонов.
Каталог uploads открывают, потому что в нем содержаться картинки, а их обыно индексируют.
В общем, вам нужно пройтись по скопированному robots.txt и просмотреть, что из написанного действительно есть на вашем сайте, а чего нет. Конечно, самому определить будет трудно. Я могу лишь сказать, что если вы что-то не удалите, то ничего страшного, просто лишняя строчка будет, которая никак не вредит (потому что раздела нет).
Так ли важна настройка robots.txt?

Конечно, необходимо иметь этот файл и хотя бы основные каталоги через него закрыть. Но критично ли важно его составление? Как показывает практика, нет. Я лично вижу сайты на одних движках с абсолютно разным robots.txt, которые одинаково успешно продвигаются в поисковых системах.
Я не спорю, что можно совершить какую-то ошибку. Например, закрыть изображения или оставить открытым ненужный каталог, но чего-то супер страшного не произойдет. Во-первых, потому что поисковые системы сегодня умнее и могут игнорировать какие-то указание из файла. Во-вторых, написаны сотни статей о настройке robots.txt и уж что-то можно понять из них.
Я видел файлы, в которых было 6-7 строчек, запрещающих индексировать пару каталогов. Также я видел файлы с сотней-другой строк кода, где было закрыто все, что только можно. Оба сайта при этом нормально продвигались.
В wordpress есть так называемые дубли. Это плохо. Многие борятся с этим с помощью закрытия подобных дублей так:
Инструмент Анализ robots.txt помогает проверить, правильно ли составлен файл robots.txt или написать содержимое файла и после проверки скопировать его в robots.txt .
Как проверить файл
Если сайт добавлен в Яндекс.Вебмастер и права на его управление подтвержденыСодержимое файла появится на странице Инструменты → Анализ robots.txt после подтверждения прав на управление сайтом.
Если содержимое отображается на странице Анализ robots.txt , нажмите кнопку Проверить .
Нажмите значок . Содержимое robots.txt и результаты анализа отобразятся ниже.В предназначенных для робота Яндекса (User-agent: Yandex или User-agent:*) разделах инструмент проверяет директивы, руководствуясь правилами использования robots.txt. Остальные разделы проверяются в соответствии со стандартом.
Ошибки в файле. Это значит, что инструмент не может обработать строку, секцию или весь файл из-за серьезных ошибок в синтаксисе, допущенных при составлении директив.Как узнать, обойдет ли робот определенный URL
Когда ваш файл robots.txt загружен в Яндекс.Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL? .
Если URL разрешен для индексирования роботами Яндекса, напротив адреса появится значок , если запрещен — отобразится адрес, выделенный красным.
Как отслеживать изменения файла
Примечание. Доступна история изменений за шесть месяцев. Максимальное количество сохраненных версий — 100.Чтобы своевременно узнавать об изменениях файла robots.txt , настройте уведомления.
Яндекс.Вебмастер регулярно проверяет обновления файла и сохраняет версии с учетом даты и времени изменения. Чтобы их посмотреть, перейдите на страницу Инструменты → Анализ robots.txt .
вы добавили сайт в Яндекс.Вебмастер и подтвердили права на управление сайтом; в Яндекс.Вебмастере есть информация об изменениях robots.txt . Вы можете: Просмотреть текущую и предыдущие версии файлаВыберите из списка Версия robots.txt версию файла. В поле ниже отобразится содержимое robots.txt , а также результаты анализа.
Вопросы и ответы
Укажите инструмент, в работе которого вы нашли ошибку, опишите ситуацию как можно подробнее, а при необходимости приложите скриншот, иллюстрирующий ситуацию.
","lang":>,"extra_meta":[>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>,>],"title":"Анализ robots.txt - Вебмастер. Справка","productName":"Вебмастер","extra_js":[[,"mods":,"__func137":true,"tag":"script","bem":false,"attrs":,"__func67":true>],[,"mods":,"__func137":true,"tag":"script","bem":false,"attrs":,"__func67":true>],[,"mods":,"__func137":true,"tag":"script","bem":false,"attrs":,"__func67":true>]],"extra_css":[[],[,"mods":,"__func69":true,"__func68":true,"bem":false,"tag":"link","attrs":>],[,"mods":,"__func69":true,"__func68":true,"bem":false,"tag":"link","attrs":>]],"csp":<"script-src":[]>,"lang":"ru">>>'>Инструмент Анализ robots.txt помогает проверить, правильно ли составлен файл robots.txt или написать содержимое файла и после проверки скопировать его в robots.txt .

Как проверить файл
Если сайт добавлен в Яндекс.Вебмастер и права на его управление подтвержденыСодержимое файла появится на странице Инструменты → Анализ robots.txt после подтверждения прав на управление сайтом.
Если содержимое отображается на странице Анализ robots.txt , нажмите кнопку Проверить .

В предназначенных для робота Яндекса (User-agent: Yandex или User-agent:*) разделах инструмент проверяет директивы, руководствуясь правилами использования robots.txt. Остальные разделы проверяются в соответствии со стандартом.
Ошибки в файле. Это значит, что инструмент не может обработать строку, секцию или весь файл из-за серьезных ошибок в синтаксисе, допущенных при составлении директив.Как узнать, обойдет ли робот определенный URL
Когда ваш файл robots.txt загружен в Яндекс.Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL? .

Если URL разрешен для индексирования роботами Яндекса, напротив адреса появится значок , если запрещен — отобразится адрес, выделенный красным.
Как отслеживать изменения файла
Примечание. Доступна история изменений за шесть месяцев. Максимальное количество сохраненных версий — 100.Чтобы своевременно узнавать об изменениях файла robots.txt , настройте уведомления.
Яндекс.Вебмастер регулярно проверяет обновления файла и сохраняет версии с учетом даты и времени изменения. Чтобы их посмотреть, перейдите на страницу Инструменты → Анализ robots.txt .
вы добавили сайт в Яндекс.Вебмастер и подтвердили права на управление сайтом; в Яндекс.Вебмастере есть информация об изменениях robots.txt . Вы можете: Просмотреть текущую и предыдущие версии файлаВыберите из списка Версия robots.txt версию файла. В поле ниже отобразится содержимое robots.txt , а также результаты анализа.
Вопросы и ответы
Укажите инструмент, в работе которого вы нашли ошибку, опишите ситуацию как можно подробнее, а при необходимости приложите скриншот, иллюстрирующий ситуацию.
Дальше нам необходимо проверить его техническую доступность, заходим в сервис проверки ответа сервера Яндекса.
Вводим путь к вашему файлу robots.txt и нажимаем проверить.
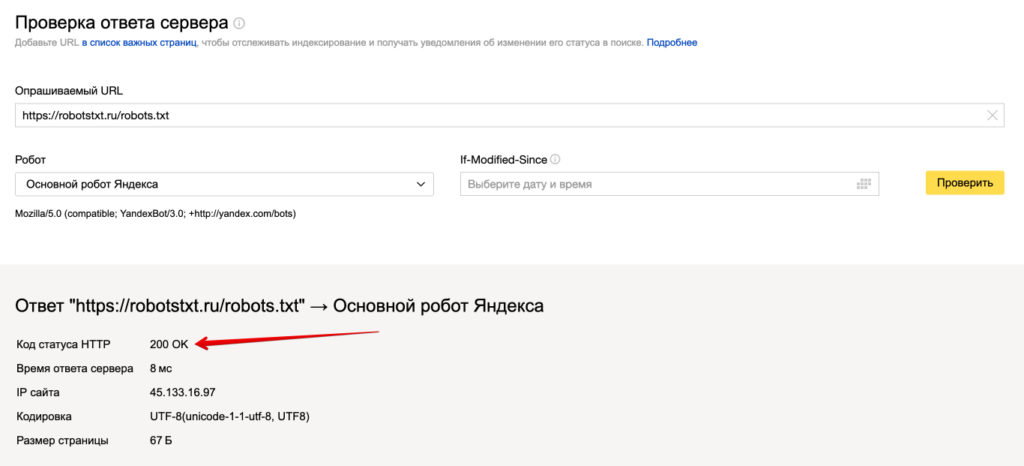
Должен отображаться ответ сервера 200. Если вы видите другие цифры, то значит robots.txt не доступен и поисковая система не сможет его прочитать.
Как проверить в Яндекс?
Как проверить в Google?
Благодаря данному инструменту любой вебмастер и оптимизатор может посмотреть, открыты ли в robots.txt конкретные URL и файлы для индексирования роботами поисковой системы Google?
Допустим, на вашем сайте есть картинка, которую вы не желаете видеть в результатах выдачи Гугла по картинкам. В инструменте Robots Testing Tool вы узнаете, закрыт ли доступ к изображению боту Googlebot-Image.
Здесь нужно прописать URL-адрес, по которому располагается изображение. Далее инструмент обработает robots.txt таким же способом, что и робот Гугла по картинкам, чтобы выяснить, запрещен ли указанный УРЛ для индексирования.
Инструкция по проверке
- Зайдите в Google Search Console и укажите свой сайт.
- Выберите инструмент проверки и проверьте инструкции, прописанные в файле Robots. Любые логические и синтаксические ошибки будут подчеркнуты, а их общее количество можно узнать внизу окна редактирования.
- В самом низу страницы найдите поле, предназначенное для указания необходимого URL-адреса.
- В меню, которое откроется справа, выберите бота.
- Кликните “Проверить”.
- После проверки инструмент покажет статус адреса: “Доступен” либо “Недоступен”. Если статус “Доступен”, значит роботам Гугла не запрещено включать в поиск изображение, а если “Недоступен”, то картинка не будет участвовать в поиске.
- Если нужно, сделайте необходимые исправления в меню и проверьте роботс снова. Имейте ввиду, что все изменения не вносятся в файл robots.txt вашего веб-ресурса автоматически.
- Сделайте копию измененного содержания и вставьте ее в robots на вашем сервере.
Что нужно знать
- Никакие изменения в редакторе не сохраняются на сервере в автоматическом режиме. Нужно скопировать измененный код и внести его в файл роботс.
- Инструмент для проверки Robots показывает результаты только для юзер-агентов Google и роботов данной поисковой системы. При этом сотрудники компании не могут давать никаких гарантий, что роботы других поисковиков будут учитывать содержание файла так же, как и Гугл.
В инструменте проверки роботса есть кнопка “Проверить”, благодаря которой ускоряется обход и включение в индекс нового robots.txt. Для передачи его в поисковую систему Google необходимо:
1. В правом нижнем углу редактора файла Robots кликнуть на кнопку “Проверить”. Так вы откроете диалоговое окно передачи.
2. Для выгрузки из инструмента кода файла, который был изменен, нажмите кнопку “Загрузить”.
3. Загрузите новый Robots в корневую папку сайта. Необходимо, чтобы URL файла выглядел следующим образом: /robots.txt.
На заметку. Если у вас нет доступа к админке, из-за чего нет возможности загружать файлы в корневой каталог домена, свяжитесь с его администратором.
4. Нажмите “Проверить”. Так вы узнаете, применяется ли новая версия Robots, которую вы хотите, чтобы роботы просканировали.
6. Удостоверьтесь в том, что измененный файл был успешно проверен роботами. Для этого необходимо обновить страницу “Инструмент проверки файла robots.txt”. После этого обновится окно редактирование, где отобразится новый код файла. В меню, открывающемся над текстовым редактором, вы узнаете, когда Googlebot первый раз увидел актуальную версию роботса.
Заключение
Следуя инструкциям выше, вы будете уверены в том, что настроили Robots.txt правильно и поисковые системы сканируют файл так, как вам нужно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Читайте также: