
Oracle sql developer создать запрос
Обновлено: 03.07.2024
Многотабличные запросы Oracle, операторы запросов и операции над наборами
1. Многотабличный запрос
1、 Внутреннее соединение
Обычно для указания внутреннего соединения используйте ключевое слово INNER JOIN, INNER можно опустить, а значение по умолчанию означает внутреннее соединение. Результат запроса содержит только строки с одинаковым общим значением поля в двух таблицах, а столбец может быть любым столбцом в двух таблицах.
2、 Внешнее соединение
Включая левое внешнее соединение, правое внешнее соединение, полное внешнее соединение
(1) ЛЕВЫЙ СОЕДИНЕНИЕ
Набор результатов включает строки, которые соответствуют условиям соединения, указанным после ON после объединения двух таблиц, и также отображаются все строки, которые соответствуют условиям поиска в таблице слева от ключевого слова JOIN. Все столбцы выбора в середине и правые таблицы - ПУСТО (NULL).
(2) ПРАВИЛЬНОЕ СОЕДИНЕНИЕ
Это обратное соединение левого внешнего соединения.
(3) ПОЛНОЕ СОЕДИНЕНИЕ
Набор результатов полного запроса внешнего соединения включает набор результатов внутреннего соединения двух таблиц и строк, которые не соответствуют условиям в левой и правой таблицах.
3、 Перекрестное соединение


В следующем примере для многотабличных запросов используются таблицы emp и dept:

Если вы не знаете, что СМИТ находится в отделе 20, измените его на:

1. Внутреннее соединение
Обычно для указания внутреннего соединения используйте ключевое слово INNER JOIN, INNER можно опустить, а значение по умолчанию означает внутреннее соединение. Результат запроса содержит только строки с одинаковым общим значением поля в двух таблицах, а столбец может быть любым столбцом в двух таблицах.
2. Внешнее подключение
Левое внешнее соединение
Результатами казни являются:
Разницу между внутренним соединением и внешним соединением можно увидеть из следующего:
Таблица A: Таблица B: Таблица C: Таблица C
Результат выполнения: (должны быть все, и ни одно из них не пусто)
Результат выполнения: (по центру таблицы C, допускается вывод NULL)
Результат выполнения: (взять за центр таблицу B, разрешить вывод NULL)
3. Перекрестное соединение
Перекрестное соединение возвращает все строки в левой таблице, и каждая строка в левой таблице объединяется со всеми строками в правой таблице. Перекрестное соединение также называется декартовым произведением.
Два, символ бюджета запроса
Существует: условие истинно, если подзапрос возвращает хотя бы одну строку. Если оператор запроса в скобках верен, запрос можно продолжить.
Не существует: условие истинно, если подзапрос не возвращает ни одной строки.
In: равно значению в результирующем наборе, возвращенном подзапросом.
Not In: не равно какому-либо значению в результирующем наборе, возвращаемом подзапросом.
> ЛЮБОЙ: больше определенного значения в результатах, возвращаемых подзапросом.
Спросите любого сотрудника, чья зарплата выше, чем у отдела 20 (больше, чем минимальная зарплата в отделе 20):
= ЛЮБОЙ: равно определенному значению в результате, возвращаемом подзапросом.
<ЛЮБОЙ: меньше определенного значения в результате, возвращаемом подзапросом.
> ВСЕ: больше всех значений в результатах, возвращаемых подзапросом.
Запросите зарплату всех сотрудников выше, чем у отдела 20 (больше, чем максимальная зарплата в отделе 20):
Три, набор операций
Операция набора заключается в объединении двух или более наборов результатов в один набор результатов.
Union union all возвращает все записи каждого запроса, включая повторяющиеся записи.
Union union возвращает все записи каждого запроса, Не включайте повторяющиеся записи 。
Пересечение Пересечение возвращает записи, общие для двух запросов.
Дополнение минус возвращает записи первого запроса за вычетом записей, оставшихся после второго запроса.
Запрос для CLERK, не связанного с отделом 30:
Последовательность автоматического увеличения операции:
Nextval автоматически добавляется на 1 каждый раз, когда используется по умолчанию, независимо от успеха или неудачи.

Как создать SQL запрос? Где писать SQL код?
В одной из прошлых статей я рассказал Вам, что такое SQL и какие СУБД бывают, но у начинающих, кто только начинает работать с базами данных, могут возникнуть определённые вопросы, например, как работать с этими базами данных, как подключиться к базе и как выполнить SQL запрос?
Обычный случай, когда человек только что установил себе какую-нибудь СУБД (например, для изучения SQL) и не знает, что делать дальше, где писать SQL код? какую программу запустить?
Или другой, еще более распространённый вариант, когда уже есть установленный SQL сервер, а начинающему программисту (IT-ку), которому сказали, что он будет еще сопровождать SQL сервер, нужно подключиться к этому серверу и выполнить какой-нибудь SQL запрос или инструкцию, а он, так как никогда не работал с серверами баз данных, конечно же, не знает, как это сделать. И все это на самом деле логично, ведь наличие установленного сервера баз данных не говорит о том, что на сервере также есть средства управления этим сервером и средства разработки SQL инструкций, так как это отдельные программы, которые устанавливаются на клиентском компьютере (но можно установить и на самом сервере).
Поэтому сегодня, специально для начинающих SQL программистов, я расскажу о том, какие инструменты нужны для того, чтобы создавать и выполнять SQL запросы к базе данных, иными словами, где писать SQL запросы. При этом я расскажу про инструменты для всех популярных СУБД: Microsoft SQL Server, Oracle Database, MySQL и PostgreSQL. Так как для каждой СУБД используются отдельные инструменты, но есть, конечно же, и универсальные инструменты, которые умеют работать одновременно практически со всеми из вышеперечисленных баз данных.
Инструменты для создания SQL запросов
Сейчас я перечислю и коротко расскажу про инструменты, которые можно использовать для написания SQL запросов и их выполнения на различных SQL серверах, при этом функционал этих инструментов не ограничивается редактором SQL запросов, на самом деле большинство современных программ для работы с базами данных являются многофункциональными, их могут использовать как разработчики, так и администраторы баз данных.
В этом материале я перечислю только некоторые инструменты, так как на самом деле их очень много. Кстати, если Вы знаете или уже пользуетесь каким-нибудь инструментом, но его в перечисленном ниже списке не обнаружили, то пишите об этом в комментариях, я думаю, всем читателям будет интересно узнать, какие еще существуют средства создания SQL запросов.
Также обязательно отмечу, что, так как здесь перечислены качественные и многофункциональные инструменты, большинство из них, конечно же, платные, но у них есть бесплатные версии или пробный период. Если Вы будете заниматься SQL разработкой на более-менее нормальном уровне, то возможно стоит и отдать деньги за понравившееся Вам решение.
Однако с другой стороны, для начинающих в целях обучения или для небольших проектов покупать отдельный, пусть и очень функциональный и удобный инструмент, я думаю, не стоит, так как достаточно будет использовать стандартные средства, которые обычно разработчики конкретной СУБД предоставляют бесплатно. Основные стандартные средства я буду отмечать, чтобы Вы понимали, от чего Вам нужно отталкиваться, если Вы начинающий.
Microsoft SQL Server
Начну я, конечно же, с Microsoft SQL Server, так как я уже достаточно долго работаю с данной СУБД. Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях.
Инструментов для работы с Microsoft SQL Server много, однако самый распространённый и популярный вариант – это, конечно же, SQL Server Management Studio.
SQL Server Management Studio
SQL Server Management Studio (SSMS) — это бесплатная графическая среда для управления инфраструктурой SQL Server, разработанная компанией Microsoft. С помощью Management Studio Вы можете разрабатывать и выполнять инструкции T-SQL, а также администрировать Microsoft SQL Server.
Среда SQL Server Management Studio – это основной, стандартный инструмент для работы с Microsoft SQL Server.
Если стандартного функционала SSMS Вам недостаточно, то для этой среды разработано очень много различных плагинов и надстроек, которые расширяют функционал Management Studio.
Более подробно про SQL Server Management Studio, включая то, как установить данную среду, я рассказывал в статье – Обзор и установка SQL Server Management Studio.
SQL Server Data Tools
SQL Server Data Tools – это еще один инструмент для работы с Microsoft SQL Server, разработанный компанией Microsoft. Данный инструмент входит в состав Visual Studio, и устанавливается он как отдельная рабочая нагрузка. Предназначен SQL Server Data Tools в первую очередь для разработчиков приложений.
Если Вы разрабатываете программы с помощью Visual Studio, при этом у Вас возникла необходимость работы с Microsoft SQL Server, то SQL Server Data Tools будет для Вас очень удобным и привычным инструментом.
dbForge Studio for SQL Server
dbForge Studio for SQL Server – это мощная среда для разработки и администрирования баз данных в Microsoft SQL Server. Разработчиком данной среды является компания Devart, у которой, кстати, есть много инструментов для работы с Microsoft SQL Server, про один инструмент я уже рассказывал в статье – Как сравнить и синхронизировать две базы данных в Microsoft SQL Server? Кроме того, у Devart есть и инструменты для работы с другими СУБД, про некоторые я сегодня еще расскажу.
Red Gate SQL Prompt
Red Gate SQL Prompt – еще один мощнейший инструмент для работы с Microsoft SQL Server. С помощью него также можно разрабатывать SQL инструкции и администрировать SQL сервер. Данную среду разрабатывает компания Redgate Software, которая специализируется на работе с данными, у нее есть инструменты и для работы с другими СУБД, но основным направлением является Microsoft SQL Server.
Navicat for SQL Server
Navicat for SQL Server – это графический инструмент для разработки и администрирования баз данных в Microsoft SQL Server. С помощью него можно создавать, редактировать и удалять любые объекты базы данных, разрабатывать и выполнять SQL запросы и инструкции, а также просматривать данные в таблицах, включая двоичные и шестнадцатеричные данные.
EMS SQL Management Studio for SQL Server
EMS SQL Management Studio for SQL Server – это комплексное решение для разработки и администрирования баз данных в Microsoft SQL Server. Разработкой занимается компания EMS, которая специализируется на разработке инструментов администрирования баз данных и приложений для управления данными. У нее много инструментов для работы с разными СУБД.
DataGrip
DataGrip – это универсальный инструмент для работы с базами данных, он умеет работать с Microsoft SQL Server, PostgreSQL, MySQL, Oracle, Sybase, DB2 и другими. Разработчиком DataGrip выступает JetBrains.
SQL Enlight
SQL Enlight – еще одно приложение для разработки T-SQL кода. Разработкой занимается компания Ubitsoft.
SQLCMD
SQLCMD – это стандартный консольный инструмент для работы с Microsoft SQL Server от компании Microsoft. Его использовать как основное средство разработки и администрирования SQL Server не получится, он в основном предназначен для каких-то служебных задач, выполнения скриптов и так далее. Его я сюда включил, так как начинающим программистам и администраторам SQL сервера об этом инструменте знать нужно.
Oracle Database
Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний.
Инструментов для работы с Oracle Database также много, вот некоторые из них.
Oracle SQL Developer
Oracle SQL Developer – это стандартный, бесплатный и основной инструмент для разработчика баз данных Oracle.
Разработкой занимается компания Oracle. С помощью Oracle SQL Developer можно разрабатывать инструкции на PL/SQL и выполнять SQL запросы.
SQL Navigator for Oracle
SQL Navigator for Oracle – это удобный и не менее популярный инструмент для работы с Oracle Database.
Navicat for Oracle
Navicat for Oracle – это инструмент для разработки и администрирования баз данных Oracle Database. Этот инструмент имеет широкий набор функций для облегчения управления данными, таких как инструмент моделирования данных, синхронизация данных, импорт и экспорт данных.
EMS SQL Management Studio for Oracle
EMS SQL Management Studio for Oracle – это комплексное решение для разработки и администрирования баз данных Oracle Database. Разработкой занимается компания EMS, продукты которой я уже упоминал сегодня.
dbForge Studio for Oracle
dbForge Studio for Oracle – еще один продукт компании Devart, который предназначен для разработки и обслуживания баз данных Oracle Database, он также имеет очень мощный функционал.
MySQL
MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила широкое применение в интернете как средство хранения данных сайтов.
Для работы с MySQL существует очень много инструментов, вот самые популярные и функциональные.
MySQLWorkbench
MySQL Workbench – это основной и стандартный инструмент для работы с MySQL.
Он позволяет осуществлять разработку на SQL и администрировать MySQL сервер.
PHPMyAdmin
PHPMyAdmin – это бесплатный веб-инструмент для работы с MySQL. Очень широкую популярность он приобрел в интернете, так как именно PHPMyAdmin используют для разработки баз данных на многих web-сайтах, а также на большинстве хостинг-провайдерах для управления базой MySQL используется именно PHPMyAdmin.
Navicat for MySQL
Navicat for MySQL – это инструмент для администрирования и разработки баз данных MySQL и MariaDB. Navicat for MySQL позволяет подключаться и работать с базами данных в MySQL и MariaDB одновременно.
dbForge Studio for MySQL
dbForge Studio for MySQL – это мощное решение для разработки и управления базами данных MySQL и MariaDB. Данный инструмент позволяет создавать и выполнять SQL запросы, разрабатывать и отлаживать процедуры и функции, а также управлять объектами баз данных MySQL с помощью удобного графического пользовательского интерфейса.
EMS SQL Management Studio for MySQL
EMS SQL Management Studio for MySQL – это еще одно комплексное и мощное решение от компании EMS, на этот раз для разработки и администрирования баз данных MySQL. Данный инструмент содержит все необходимые компоненты для работы с MySQL: редактор SQL запросов, средство импорта, экспорта и сравнения данных и много других, предназначенных не только для разработчиков, но и для администраторов и аналитиков данных.
SQL Maestro for MySQL
SQL Maestro for MySQL – это еще один инструмент разработки и администрирования баз данных MySQL и MariaDB.
PostgreSQL
PostgreSQL – эта бесплатная система управления базами данных, и она очень популярна и функциональна.
Для работы с PostgreSQL можно использовать следующие инструменты.
pgAdmin
pgAdmin – это основное, стандартное средство для разработки баз данных PostgreSQL, которое распространяется бесплатно.
pgAdmin достаточно удобный инструмент для разработчика, с помощью него можно разрабатывать SQL инструкции, выполнять SQL запросы, создавать объекты базы данных и многое другое.
EMS SQL Management Studio for PostgreSQL
EMS SQL Management Studio for PostgreSQL – это комплексное решение для разработки и администрирования баз данных PostgreSQL. Данный инструмент так же, как все остальные продукты компании EMS, имеет очень широкий функционал от простого редактора SQL запросов до инструмента сравнения данных.
Navicat for PostgreSQL
Navicat for PostgreSQL – это простой графический инструмент для разработки баз данных PostgreSQL. Он позволяет писать и выполнять SQL запросы любой сложности.
dbForge Studio for PostgreSQL
dbForge Studio for PostgreSQL – это еще один мощный инструмент от компании Devart, на этот раз для работы с PostgreSQL. Он позволяет разрабатывать и выполнять запросы, редактировать код в удобном интерфейсе, формировать отчеты, модифицировать данные, а также осуществлять импорт и экспорт данных.
psql
psql – это стандартная консольная утилита для работы с PostgreSQL. Используется в основном для автоматизации различных служебных задач, хотя вести SQL разработку в ней также можно.
DataGrip
Также осуществлять разработку баз данных PostgreSQL можно и с помощью уже упомянутого в этой статье универсального инструмента DataGrip от компании JetBrains.
Выводы
Как видите, существует очень много инструментов для работы с базами данных, при этом многие компании специализируется на выпуске программ для баз данных, и у них есть версии для каждой популярной СУБД. Такие инструменты очень функциональны, и они, конечно же, платные. Но, как я уже отмечал, функционала стандартных средств, которые предоставляются бесплатно, для создания и выполнения SQL запросов будет вполне достаточно.

1- Введение
PL/SQL (Procedural Language/Structured Query Language) это процедурно-ориентированный язык программирования использующийся для Oracle SQL. Является расширением Oracle SQL.
PL/SQL включает компоненты процедурно-ориентированного языка включая условие и цикл. Он позволяет объявлять константы и переменные, процедуры и функции, виды данных и переменные видов данных, и trigger. Он может обрабатывать исключения (ошибки времени запуска) Массив так же поддерживается для использования коллекций в PL/SQL. От версии 8 и далее он включает объектно-ориентированные функции. Может создать такие единицы PL/SQL как процедуры, функции, пакеты, виды данных, triggers, которые хранятся в базе данных для переиспользования приложением, чтобы взаимодействовать с приложениями Oracle.
Примечание: В следующих изображениях я использую инструмент PL/SQL Developer версии 8.x, но нет отличия если вы используете PL/SQL Developer версии 10.x или другую версию.
2- Что нужно чтобы начать с PL/SQL?
Чтобы иметь быстрый доступ к PL/SQL вам нужен инструмент программирования. По моему опыту работы, вы можете использовать PL/SQL Developer, это визуальный инструмент для работы с Oracle и программирования PL/SQL.
Вы можете посмотреть инструкцию установки и конфигурации PL/SQL по ссылке:
3- Обзор PL/SQL
Есть некоторые определения, которые вы должные четко знать при программировании с PL/SQL:
- Каждая команда SQL заканчивается точкой с запятой (;)
- Команды "языка определения данных" (Data Definition Language - DDL) не используются в PL/SQL
- Команда SELECT.. INTO возврщает много строк создающих exception ( > 1 строки).
- Команда SELECT .. INTO не возвращает строки создающие exception
- Команды "языка манипулирования данными" (Data Manipulation Language - DML) может подействовать на многие строки данных.
- Использовать оператор := чтобы дать значение переменной.
PL/SQL организован по блокам команд. Один блок команды может содержать подблок команд внутри.
4- Базовые команды PL/SQL
Здесь я представляю обзор команд PL/SQL. Вы поймете больше через примеры в следующих частях.
4.1- Команда If-elsif-else
4.2- Не предопределенный цикл (LOOP)
4.3- Предопределенный цикл (FOR LOOP)
4.4- Цикл while (WHILE)
5- Начать с PL/SQL используя PL/SQL Developer
Для начала вам нужно открыть PL/SQL Developer, и войти как пользователь learningsql:

В PL/SQL Developer создать новое окно SQL:



Данные рекомендации взяты мной из руководства Oracle по настройке базы данных, со временем они практически не меняются, посмотреть их можно здесь, это глава 11.5. Ссылка может не работать, все зависит от того, как долго Oracle решит хранить этот фрагмент документации в интернете.
Не используйте SQL-функции в предикатах. Любое выражение в котором используется колонка (expression), например функция, использующая колонку, как аргумент, приведет к тому, что индекс для данной колонки (если он есть) использоваться не будет, даже если это уникальный индекс. Хотя, если для колонки имеется составной индекс (function-based) на основе применяемой в предикате функции, то он может быть использован.
где numexpr выражение числового типа, то Oracle преобразует ваше условие в:
и индекс использован не будет.
Где по числовой колонке numcol построен индекс.
План запроса.
Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами, т.е. написать несколько разных запросов, которые дадут один и тот же результат. Это, однако не означает, что база данных эти запросы будет выполнять по-разному. Также неверно мнение о том, что структура запроса может повлиять на то, как Oracle будет его выполнять, это касается порядка временных таблиц, JOINS и условий отбора в WHERE. Решение о том, как построить запрос принимает оптимизатор Oracle. Алгоритм получения сервером данных для конкретного запроса называют планом запроса.
Практически все продукты для работы с базой данных Oracle позволяют просмотреть план конкретного запроса. Так как слушатели этих лекций используют PL/SQL Developer, то для получения плана запроса в нем необходимо сделать следующее:
Существует стандартный механизм получения плана запроса. Для этого используется конструкция (команда) EXPLAIN PLAN FOR:
План запроса будет выведен в виде таблицы с одним полем, выглядит он так:
Важно ! Во всех планах запросов, первостепенное значение имеют колонки операций и названия объектов над которыми эти операции производятся. Все остальные колонки имеют оценочный характер, часть из них формируется на основе статистики, которая может устареть или вообще отсутствовать. При анализе плана запроса вы должны представлять объемы записей в таблицах, а также примерный алгоритм соединения таблиц.
В приведенном выше примере показан план запроса, полученный с помощью EXPLAIN PLAN FOR, более наглядную картину дает окно плана запроса в PL/SQL Developer:
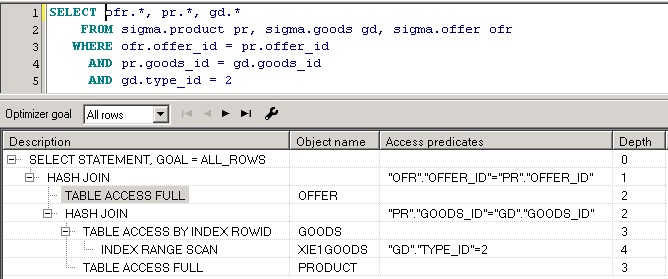
План всегда имеет иерархическую структуру. Операция соединения результирующих наборов оперирует парами дочерних операций. Операция получения данных может использовать вспомогательную операцию, такую, например, как сканирование индекса.
Данные результирующих наборов получаются в порядке следования этих наборов в плане запроса. Операция получения данных результирующего набора может состоять из нескольких шагов, которые характеризуются глубиной операции (колонка Depth).
При анализе плана в первую очередь необходимо обращать внимание на способы, с помощью которых получены данные результирующих наборов.
Некоторые термины в плане запроса.
План запроса имеет форму таблицы, один из столбцов которой описывает тип производимых сервером операций. Вот некоторые из них, которые встречаются наиболее часто:
Анализ плана запроса.
При анализе плана запроса вам необходимо примерно представлять объемы записей в таблицах и наличие у них индексов, которые могут пригодиться при фильтрации записей. Для доступа к данным Oracle использует несколько стратегий, какие из них выбраны для каждой из таблиц можно понять из плана запроса. При просмотре плана, вам необходимо решить, правильная ли выбрана стратегия в том или ином случае. Ниже приведены краткие описания способов доступа и механизмов отбора записей при соединениях результирующих наборов.
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным таблицы быстрее осуществлять через индекс, но это не так. Иногда дешевле прочитать всю таблицу целиком, чем прочитать, например, 80% записей таблицы через индекс, так как чтение индекса тоже требует ресурсов. Очень не желательна ситуация, когда эта операция стоит первой в объединении наборов записей и таблица, которая читается полностью, большая. Еще хуже ситуация с большой таблицей на второй позиции в объединении, это означает, что она также будет прочитана полностью, как минимум, один раз, а если объединение производится через NESTED LOOPS, то таблица будет читаться несколько раз, поэтому запрос будет работать очень долго.
Nested Loops.
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане запроса) объединяется с помощью условия, позволяющего эффективно выбрать записи из второго набора. Важным условием успешного использования такого соединения является наличие связи между основным и второстепенным набором записей. Если такой связи нет, то для каждой записи в первом наборе, из второго набора будут извлекаться одни и те же записи, что может привести к значительному увеличению времени запроса. Если вы видите, что в плане запроса применен NESTED LOOPS, а соединяемые наборы не удовлетворяют этому условию, то налицо ошибка.
Hash Joins.
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения в памяти хэш-таблицы по ключу соединения. Затем он сканирует большую таблицу, используя хэш-таблицу для нахождения записей, которые удовлетворяют условию объединения.
Оптимизатор использует HASH JOIN, если наборы данных соединяются с помощью операторов и ключевых слов эквивалентности (=, AND) и если присутствует одно из условий:
■ Необходимо соединить наборы данных большого объема.
■ Большая часть небольшого набора данных должна быть использована в соединении.
Sort Merge Join.
Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую стратегию, если наборы данных уже отсортированы ранее, и если дальнейшая сортировка результата соединения не требуется. Обычно это имеет место для наборов, которые соединяются с помощью операторов , >=. Для этого типа соединения нет понятия главного и вспомогательного набора данных, сначала оба набора сортируются по общему ключу, а затем сливаются в одно целое. Если какой-то из наборов уже отсортирован, то повторная сортировка для него не производится.
Cartesian Joins.
Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с какой-либо другой таблицей в запросе. В этом случае произойдет объединение каждой записи из одного набора данных с каждой записью в другом. Такое соединение может быть выбрано между двумя небольшими таблицами, а в дальнейшем этот набор данных будет соединен с другой большой таблицей. Наличие такого соединения может обозначать присутствие серьезных проблем в запросе, особенно, если соединяемые таблицы по MERGE JOIN CARTESIAN. В этом случае, возможно, упущены дополнительные условия соединения наборов данных.
Хинты.
Использование хинтов.
Хинт ставится после ключевого слова, которое определяет некую цельную конструкцию запроса, в данном разделе речь пойдет о хинтах в запросах к данным, т.е. тех, которые оформляются оператором SELECT и ключевых словах, используемых в сочетании с ним. Хинт указывается в закрытом комментарии после оператора:
В данном примере используется хинт RULE.
FIRST_ROWS.
Данный хинт дает указание оптимизатору выбрать такой план запроса при котором первые записи результатов будут получены максиально быстрым способом. Хорош при отладке запроса, чтобы убедиться, что выдается то, что необходимо. Если предполагается, что запрос вернет много записей, то при использовании такого хинта он может работать дольше.
ORDERED / LEADING.
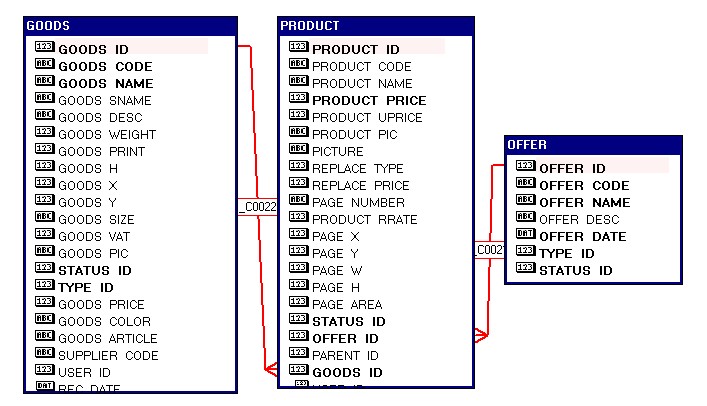
При использовании этого хинта оптимизатор соединяет наборы данных в том порядке, в каком они следуют после оператора FROM. Вот пример разных последовательностей:
Порядок наборов данных необходимо выбирать аккуратно, чтобы соединяемые объекты имели какое-то условие связи в WHERE или после ключевого слова ON. Например в приведенном выше примере 4 версия списка во FROM приведет к перемножению таблиц GOODS и OFFER, так как они не связаны друг с другом условиями.
Данный хинт часто бывает полезен, если статистика по таблицам не собрана, план запроса не верный, и вам точно известно, как должны соединяться таблицы. При использовании данного хинта старайтесь выстроить порядок соединения так, чтобы тяжесть обработки данных следовала в сторону увеличения, т.е. сначала соедините наборы поменьше или с хорошими условиями отбора, чтобы результат их соединения был наименьшим по количеству записей, затем подключайте наборы данных большего размера.
Более удобен в использовании хинт LEADING. Он позволяет соединить наборы данных в порядке перечисления их (или их алиасов) в списке аргументов хинта:
Порядок связи в этом примере будет такой: product -> offer -> goods. Использование этого хинта предпочтительнее при отладке, если список наборов данных большой.
MATERIALIZE.
Дает указание оптимизатору построить временную таблицу (материализовать результаты) для запроса, к которому этот хинт применяется, работает только в конструкции WITH. Очень полезен при обработке больших объемов данных, так как позволяет разбить запрос на части, в этом случае улучшается читабельность запроса, а также может быть получен правильный план. Пример использования:
План запроса выглядит так:
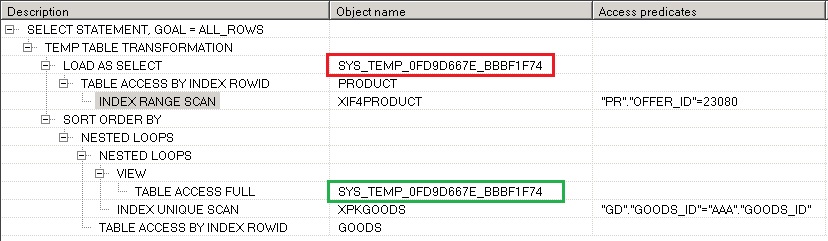
Красным цветом помечена таблица при ее создании, зеленым ее использование в соединении.
INDEX.
Дает указание оптимизатору использовать индекс при чтении данных из таблицы. Полезен тем, что может предотвратить чтение всего содержимого таблицы, если вы считаете, что этого делать не нужно. Пример использования:
Этот хинт сработает в том случае, если у таблицы есть указываемый индекс, и его можно использовать на основе одного или нескольких условий при получении данных таблицы. В приведенном примере в составе индекса есть поле OFFER_ID на второй позиции и он может быть использован, план запроса выглядит в этом случае так:

Комбинации хинтов.
Использование комбинации хинтов допустимо. Нужный эффект можно получить, если хинты в одном запросе не протеворечат друг другу. При записи хинты разделяются пробелами:
В данном примере используется хинт для установки порядка соединения наборов данных и способа доступа к таблице, противоречия в их использовании нет.
Читайте также: