
Raid scrubbing что это
Обновлено: 07.07.2024
Несколько лет назад я предупреждал, что RAID 5 перестанет работать в 2009 году. Конечно, поставщики сетевых хранилищ не рекомендуют RAID 5. Они в настоящее время рекомендуют RAID 6, который защищает от отказов двух дисков в массиве. Но в 2019 году даже RAID 6 не будет защищать ваши данные. Вот почему.
RAID 6 = (RAID 5) 2
Я писал, что и RAID 6 будет иметь ограниченный срок службы:
Хорошая новость: Левенталь обнаружил, что уровень защиты RAID 6 будет так же хорош до 2019 года, как раньше был RAID 5.
Суть проблемы
Проблема с RAID 5 в том, что жесткие диски имеют ошибки чтения. В SATA дисках по спецификации допускается коэффициент неисправимых ошибок чтения (URE) на уровне 10 14 . Это означает, что один раз на 10 14 бит диск просто не сможет прочитать данные.
10 14 бит = 100000000000000/8/512 секторов = 24 414 062 500 секторов
реальный размер 2тб диска = 3 907 029 168 секторов
Когда в RAID 5 массиве из 7 дисков SATA по 2 ТБ один жесткий диск выходит из строя, у вас остается 6 дисков по 2ТБ. И пока контроллер RAID будет делать rebuild, весьма вероятно случится ошибка чтения (URE). После этой ошибки реконструкция RAID массива становится невозможна.
Итого существует 62% вероятность потерять данные из-за неисправимой ошибки чтения в массиве RAID5 из семи SATA дисков с одним сбойным диском.
RAID 6
RAID 6 решает эту проблему путем создания второй контрольной суммы. Вы можете потерять один диск, поймать ошибку чтения URE и все равно успешно пройти rebuild.
В чем проблема?
Упрощаем: большие диски = дольше rebuild + больше скрытых ошибок -> больше шансов сбоя RAID 6.
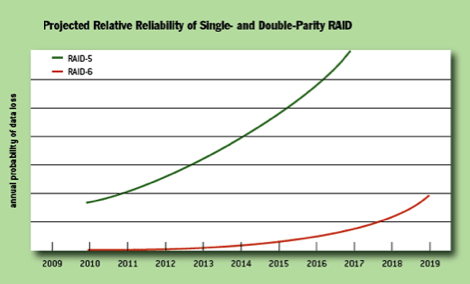
Прогноз Левенталя относительной надежности RAID с одинарной и двойной четностью
К 2019 году RAID 6 будет не более надежным, чем RAID 5 является сегодня.
Выводы
Для корпоративных пользователей этот вывод будет полезной информацией. В то время как тройная четность в массивах решит проблему защиты данных, придется идти на значительные компромиссы.
Обычные пользователи могут расслабиться. Домашний RAID является изначально плохой идеей, лучше делайте чаще резервные копии с диска на диск и используйте сервисы онлайн бэкапа ценных данных.
Основными факторами определяющими будущий уровень массива являются:
- скорость
- цена
- отказоустойчивость
В итоге отношение этих трёх факторов даёт нам три возможных варианта нужного уровня рейд
Может показаться, что для RAID5, RAID6 нужно вложить больше денег, однако итоговая ёмкость массива при том же количестве дисков, что и в RAID1+0 будет больше. А это может стать определяющим фактором
Действительно ли вам нужен RAID0?
Перед тем как строить RAID0 на шпиндельных дисках обратите внимание на диски SSD. В зависимости от ваших потребностей вам может быть выгоднее купить один диск SSD, чем пару шпиндельных дисков с 7200rpm. С другой стороны если вы планируете высокоёмкостный массив и важно, чтобы был быстрый доступ к данным, то лучше смотреть в сторону шпиндельных дисков с 10000rpm в качестве кандидатов. Разница в цене между одним SSD и парой шпиндельных дисков может быть достадочно большой
Таким образом стоимость высокоёмкостного массива RAID0 или даже RAID10 на базе шпиндельных дисков будет значительно меньше. И большинстве случаев такой RAID вполне способен удовлетворить ваши потребности. Если же вам не нужен такой большой массив, то лучше взять один SSD вместо RAID0 или два SSD в RAID1 вместо RAID10. Кроме того минимальное время доступа таких RAID не уменьшается. Именно поэтому на сегодняшний день SSD будет лучшим выбором
RAID5 или RAID6?
Если вы планируете строить RAID5 общей ёмкостью более 15Тб, то лучшим решением будет всё же RAID6
RAID6 в этом смысле более надёжен
Горячая замена (hot spares)
Резервный диск hot spare является хорошим дополнением к отказоустойчивости массива повышая его надёжность. Если вылетел один из дисков в отказоустойчивом массиве (RAID1, RAID10, RAID5 или RAID6) массив стал уязвим. В таком случае вам нужно физически вытащить сбойный диск и на его место установить новый. Только после этого начнётся перестройка массива. Наличие диска hot spare позволяет контроллеру немедленно приступить к восстановлению, без вторжения со стороны администратора. Чем больше дисков в вашем массиве, тем больше вероятность того, что вам потребуется hot spare диск
Технология hot spare особенно эффективна, когда единственный диск hot spare доступен для нескольких массивов. Например в восьмидисковом NAS лучше построить RAID6, чем RAID5. Потому что в случае с RAID5 диск hot spare работает вхолостую ожидая своей участи, в то время как его лучше использовать в RAID6, что сделает операции чтения эффективнее и массив более отказоустойчивым. С другой стороны при наличии двух массивов RAID5 диск hot spare одинаково быстро доступен для любого из них, тем самым сокращая и без того немалые расходы
Программный RAID все-таки жив
Не недооценивайте реализацию RAID средствами ОС
- такой RAID обеспечивает аналогичную, а может даже лучшую надёжность, по ставнению с интегрированими контроллерами начального уровня. Он также более надёжен, чем тот же RAID построеный на базе pci-raid-контроллера за 20$
- RAID средствами ОС легче перенести с сервера на сервер. Нет риска в длительном простое, пока вы купите новый аналогичный контроллер на замену вышедшему из строя. Ему не нужны драйвера pci-raid-контроллера. Вы просто переносите диски на новое железо и всё
- в случае с RAID0, RAID1, RAID10 у pci-raid-контроллера нет особых преймуществ, потому что он не занимается вычислительними операциями. Я не умаляю возможности pci-raid-контроллера работать с кешем записи, но для этого он должен комплектоваться BBU
- потому многие современные NAS для домашнего пользования и малого бизнеса используют програмный RAID
Побочный эффект такого RAID:
- нет гарантий в надёжной загрузке системы
- значительное падение производительности сервера во время перестройки массива
Тестирование RAID
Свежепостроеный отказоустойчивый массив (RAID1, RAID10, RAID5, RAID6) нуждается в тестировании для того, чтобы знать как поведёт себя RAID в случае отказа одного из дисков
- если ваше устройство поддерживает hot swap, вытягивайте любой диск на живой системе
- если устройство не поддерживает hot swap, вытягивайте диск только после выключения устройства
После этого вы должны убедиться, что работающая система ведёт себя ожидаемым образом, массив доступен, есть возможность записывать и считывать данные. Желательно, чтобы вы получали уведомления о нештатной ситуации на мейл или по SMS. Средствами ПО контроллера проверьте определяется ли порт контроллера со сбойным диском. После этого отключите UPS от сети, через определённый период времени система должна корректно завершить работу
Тестирование лучше проводить до ввода в устройства эксплуатацию, чтобы вы знали как реагировать если что. Да и лишняя головная боль вам ни к чему если вдруг что-то пойдет не так
- выход из строя RAID-контроллера, сопровождается как правило простоем пока купят аналогичный, а если такого нет впереди как правило бессоная ночь с восстановлением данных
- выход из строя большего числа дисков, чем это допустимо
- намеренное или случайное удаление или искажение пользователем рабочих файлов
- пожары, наводнения и прочий форс-мажор
- да мало ли что еще может быть
Всегда на замену должны быть диски нужного размера, всегда! Должен быть квалифицированный человек которорый сможет выполнить замену дисков для восстановления массива. Время реакции на возникшую проблему должно быть минимальным, иначе вы рискуете не пережить следующий подобный отказ. Но всё дело в том, что вы не будете знать когда нужно предпринимать экстренные меры если у вас не будет системы мониторинга
- регулярная проверка SMART параметров дисков
- очень желательно, чтоб ваш RAID-контроллер умел scrubbing. Scrubbing работает в моменты простоя считывая и контролируя характеристики чтения, что даёт вам возможность узнать о потенциальных сбойных секторах раньше, чем они появятся реально
- любое необъяснимое падение производительности может означать проблемы с диском
Восстановление RAID
Существует один известный и широко обсуждаемый вопрос относительно RAID5.
Для того, чтобы восстановить массив из N дисков по C терабайт каждый, нужно считать C*(N-1) данных. Число бит которые необходимо считать определяется формулой
b = C * (N-1) * 8 * 10 12
Вероятность перестройки массива с удачным исходом определяется формулой
P = q b
Величину p указывает производитель в спецификации диска, и обычно она равна 10 -15 ошибок чтения на один бит
Значение URE производителя
Вероятность краха при
Эти расчёты выставляют проблему в худшем свете, чем это есть на самом деле и основаны они на несколько наивных утверждениях:
- сбойные биты встречаются через одинаковые промежутки времени и расположены равномерно по всем дискам массива
- единственная ошибка считывания во время перестройки массива убивает весь массив
Но оба эти утверждения не соответствуют дейтвительности, что делает рузультаты вычислений абсолютно бесполезными. Кроме того сама идея учёта ошибоксчитывания на по-битном уровне кажется сомнительной, учитывая то, что блочные устройства не могут считывать меньше, чем 512 байт данных за одну транзакцию
Таким образом утверждение в начале этого раздела может быть переопределено в нечто более практичное
Существует 50% вероятность того, что невозможно будет перестроить массив RAID5 ёмкостью 12Тб
Тоже самое можно сказать иначе
Если у вас есть 10Тб массив уровня RAID0, то существует вероятность 50%, что вы не сможете прочитать данные даже если вы их записали мгновение тому назад 1
Тем не менее никто не говорит о том, что RAID0 мёртв. Выше сказанное можно переформулировать по-другому
Подобные утверждения не могут быть правдой
перевод Александр Черных
системный администратор
Системный администратор. В сисадминстве с 2000 года. Участник cyberforum

В системах хранения данных критически важны сохранность и время восстановления в случае сбоя. Свою ценность, а в некоторых задачах и более высокую, имеет скорость работы накопителей. Использование RAID-массивов в различных конфигурациях — это поиск компромисса между перечисленными параметрами.
RAID — это технология объединения двух и более накопителей в единый логический элемент с целью повышения производительности и (или) отказоустойчивости отдельно взятого элемента массива.
RAID-массивы классифицируются по следующим параметрам:
- по исполнению RAID контроллера;
- по типам поддерживаемых интерфейсов накопителей;
- по поддерживаемым уровням RAID.
RAID-контроллеры: аппаратные и не очень
По исполнению контроллеры делятся на программные и аппаратные. Программные реализуются непосредственно средствами операционной системы или на уровне материнской платы. Последние также известны как интегрированные, а также Fake-RAID. Они работают быстрее чисто софтверных решений за счет специального чипа для управления массивом. Недавно публиковался текст о развертывании таких технологий. Дополнительной железки при этом никакой нет и в любом случае будут использоваться ресурсы вычислительной машины.
Аппаратные RAID-контроллеры выполняются в форм-факторе платы PCIe либо в составе внешнего автономного устройства — дискового массива.
Они имеют на борту собственные процессор, память, BIOS и специальный интерфейс для конфигурации. Платы PCIe также комплектуются дополнительными модулями, сохраняющими данные, если произойдет сбой в электропитании: BBU с Li-Ion аккумулятором и ZMCP на базе суперконденсатора.

Оба модуля позволяют сделать сэйв содержимого кэша. После восстановления работы эти данные будут немедленно записаны на диск. Дисковый массив, будучи автономным, располагает собственными блоком питания и системой охлаждения.

Накопители подключаются к плате либо кабелями напрямую, либо через платы расширения. Автономные дисковые массивы содержат все накопители внутри себя, а наружу смотрит все тот же интерфейс PCIe (есть и другие варианты, например, USB 3.2 и Thunderbolt 3). Кстати, известный вид дисковых массивов — сетевое хранилище данных (NAS).
Что можно подключать к RAID-контроллеру
Следующий важный параметр, по которому различаются RAID-массивы, это поддержка интерфейсов накопителей. Не будем тревожить склеп с IDE-дисками, а констатируем, что по большому счету применяются три типа: SATA, SAS и NVMe. SAS — удел серверов, а вот остальные применяются повсеместно.
Есть программные и аппаратные RAID-контроллеры, которые умеют управлять массивом дисков с одним из интерфейсов. В формате PCIe есть и такие платы, которые реализуют режим Tri-Mode, позволяющий работать со смешанным составом накопителей.

Уровни RAID
Разобравшись с основными конструктивными особенностями RAID-контроллеров, перейдем к главной характеристике — поддержке уровней RAID. В подавляющим большинстве контроллеры работают с уровнями 0, 1, 1E, 10, 5, 5EE, 50, 6, 60. Другие занесены в красную книгу и на практике встречаются редко. Простейшие программные контроллеры позволяют создать RAID 0 и 1. Более продвинутые добавляют RAID 10 и 5. В аппаратных, как правило, такой перечень минимален, и многие платы поддерживают весь спектр уровней. Рассмотрим подробнее каждый из них.
Несколько важных нюансов для понимания эффективных объема и быстродействия, получаемых в результате объединения в массив:
- при использовании накопителей разного объема контроллер «обрезает» объем каждого из них до наименьшего из используемых. Если у вас есть много дисков 4 ТБ и один 2 ТБ, то в массиве все диски будут восприниматься как 2 ТБ;
- при использовании накопителей с разными скоростями ввода/вывода и задержками, то операции доступа будут осуществляться с наихудшими из всех параметров. Другими словами, самым быстрым дискам придется ждать, пока отработает самый медленный.
RAID 0

Единственный массив, который не совсем оправдывает название, поскольку не обладает избыточностью. При этом скорость и эффективный объем максимальны. Данные разбиваются на одинаковые блоки, равномерно записываемые на все диски по очереди. Эти блоки называются страйпами, отсюда и сам RAID 0 часто именуют страйпом. Считывание данных также происходит параллельно. Здесь конечно же есть свое но.
Дело в том, что прирост производительности не прямо пропорционален количеству дисков (как хотелось бы). В силу специфики накопителей, особенно механических, выигрыш в конфигурации RAID 0 хорошо заметен только на операциях последовательного чтения. Другими словами, при работе с большими файлами. Типичная область применения — игры, видеомонтаж и рендеринг. При условии, что регулярно производится резервирование на сторонние накопители. Наряду с этим при случайном доступе к файлам разница с отдельно взятым диском уже не так ощутима. Более позитивная картина наблюдается в случае твердотельных накопителей, но они и так удовлетворяют большинству запросов по быстродействию.
В общем, в современных реалиях RAID 0 далеко не всегда оправдает свое применение, а основная задача RAID-массива все же в повышении надежности хранения данных.
Обратная сторона медали за скорость как раз в отсутствии избыточности, что означает нулевую отказоустойчивость. В случае сбоя хотя бы одного из элементов массива, восстановление всего содержимого практически невозможно.
RAID 1

RAID 1, известный как «зеркало», представляет собой другую крайность. Он максимально избыточен — в нем производится 100 % дублирование данных. Этот процесс «съедает» ровно половину объема массива. Число дисков в нем, соответственно, четное. Позволяет увеличить скорость чтения, но синхронная скорость записи в некоторых случаях падает. При отказе одного из дисков работа автоматически продолжается с дублером. Если доступна функция горячей замены дисков, то восстановление штатного режима происходит без остановки. RAID 1 идеален для чувствительных данных.
RAID 5

Состоит минимум из трех накопителей, при этом доступный объем уменьшается на один. Данные записываются в страйпы на все диски кроме одного, на котором размещается контрольная сумма этой части данных. Запись этого блока также чередуется между всеми накопителями, распределяя равномерную нагрузку. Если их больше четырех, то скорость чтения будет выше чем в RAID 1, но запись будет осуществляться медленнее. Контрольные суммы позволяют достать информацию в случае выхода из строя одного из элементов. Сама операция восстановления вызывает повышенную нагрузку на оставшиеся диски. Значительно падает производительность и риск утери всех данных в случае отказа еще одного диска. Желательно иметь опцию горячей замены для оперативного возвращения в нормальный режим работы.
Со всеми плюсами и минусами эти три уровня наиболее распространены и просты в развертывании.
RAID 6

Развитие RAID 5 по части надежности, позволяющее пережить потерю двух дисков. В данной конфигурации в каждом проходе пишется две независимые контрольные суммы на два накопителя. Требуется минимум четыре диска, из которых два уйдет на описанный алгоритм повышения отказоустойчивости. При этом скорость записи будет еще ниже, чем у RAID 5.
Следующие уровни — производные и комбинации перечисленных.
RAID 10

Неплохо было бы объединить достоинства RAID 0 (производительность) и RAID 1 (отказоустойчивость)? Встречайте RAID 10: страйп и зеркало, два в одном. Но и недостатки не забудьте — по-прежнему половина объема уходит на резерв. А что делать, за надежность приходится платить. В этом плане менее экономичен, чем RAID 5 И RAID 6, но более прост в восстановлении после сбоя.
RAID 50

По похожей схеме получаем RAID 50. Здесь уже страйпы не зеркалируются, а распределяются по двум и более массивам RAID 5. Требуется от шести дисков, скорость чтения значительно увеличивается. Кроме того, нивелируется и слабое место RAID 5 и RAID 6 — низкая скорость записи. Отрицательная сторона опять лежит в плоскости экономики. Из эффективного объема выпадают два диска, как и RAID 6, при этом массив выдержит потерю только одного.
RAID 60

Данный гибрид RAID 0 и RAID 6 призван решить проблему производительности последнего. Отказоустойчивость остается на том же уровне, как и часть объема накопителей, отводимая на реализацию алгоритмов контроля целостности данных. Дисков для такого удовольствия понадобится как минимум восемь.
RAID 1E

Еще одна вариация совмещения алгоритмов зеркалирования и чередования данных. Записанные на одной итерации страйпы повторно записываются на следующей, но в обратном порядке. Таким образом в RAID 1E можно использовать три диска. Массив останется тем же зеркалом с эффективным объемом, равным половине от исходного.
RAID 5EE

Один из вариантов использования RAID 5 с резервным диском. Отличается тем, что этот диск не простаивает до выхода из строя одного из элементов массива, а используется наряду с другими. На каждой итерации помимо страйпов данными и контрольной суммой записывается резервный блок. Сделано это для ускорения процесса сборки массива в случае нештатной ситуации. Платой за такую опцию становится второй диск, исключаемый из эффективного объема RAID 5EE.
В таблице ниже приведены сравнительные характеристики рассмотренных уровней RAID.

Не забудем и про массив с незатейливым названием JBOD (дословно переводится как «просто связка дисков»). Строго говоря, он не является RAID-массивом. Это объединенные в один несколько дисков без дополнительной функциональности. Позволяет развернуть логический диск с объемом, который недоступен в рамках одного накопителя. Такой диск полезен для перемещения файлов больших размеров в несколько терабайт.
Вместо заключения напомним самое главное правило для всех, кто хранит данные в RAID-массиве: RAID-массив ≠ бэкап! Регулярно делайте резервные копии данных на независимые носители и да пребудет с вами сила.

Visitors have accessed this post 2581 times.
Автор — Максим Рязанов
Давайте продолжим нашу тему про RAID. Напомню, что первую часть статьи можно найти тут.
Обслуживание RAID
Очистка RAID — Scrubbing
Рекомендуется регулярно выполнять scrubbing данных, чтобы проверять и исправлять ошибки. В зависимости от размера / конфигурации массива очистка может занять несколько часов.
Чтобы инициировать scrubbing данных:
Операция проверки сканирует диски на наличие поврежденных секторов и автоматически восстанавливает их. Если она находит хорошие сектора, которые содержат неверные данные (данные в секторе не согласуются с тем, что это должно быть по данным с другого диска), то никаких действий не предпринимает, но событие регистрируется (см. ниже). Это позволяет администраторам проверять данные в секторе и полученные при восстановлении секторов из избыточной информации и выбирать те, что нужно хранить.
Как и во многих задачах, относящихся к mdadm, состояние scrub можно узнать, прочитав / proc / mdstat.
Чтобы безопасно остановить текущий scrubbing данных:
Примечание. Если система будет перезагружена после того, как частичный scrubbing был приостановлен, он начнется заново.
Когда scrubbing завершен, администраторы могут проверить, сколько блоков (если они есть) были помечены как плохие:
Общие замечания по scrubbing:
В качестве альтернативы пользователи могут использовать восстановление в /sys/block/md0/md/sync_action, но это не рекомендуется, поскольку в случае обнаружения несоответствия в данных они будут автоматически обновляться. Опасность заключается в том, что мы действительно не знаем, является ли правильным паритет или блок данных (или какой блок данных в случае RAID1). И получит ли операция правильные данные вместо неверных.
Хорошей идеей будет установить задание cron как root для планирования периодической очистки. Смотрите raid-check, который может помочь с этим. Чтобы выполнить периодическую очистку с использованием systemd таймеров вместо cron, см. раздел raid-check-systemd, который содержит тот же сценарий вместе со связанными файлами модулей таймера systemd.
Для типичных массивов с жесткими дисками scrubbing может занимать приблизительно шесть секунд на гигабайт (то есть один час сорок пять минут на терабайт), поэтому спланируйте запуск задания cron или таймера соответствующим образом.
Заметки по scrubbing для RAID1 и RAID10
Из-за того, что записи RAID1 и RAID10 в ядре не буферизованы, массив может иметь ненулевое число несоответствий, даже если он исправен. Эти ненулевые значения будут существовать только в переходных областях данных, где они не представляют проблемы. Но мы не можем определить разницу между счетчиком, отличным от 0, который находится просто в переходных данных, и счетчиком, отличным от 0, который указывает на реальную проблему. Это является источником ложных срабатываний для массивов RAID1 и RAID10. Тем не менее по-прежнему рекомендуется регулярно выполнять очистку, чтобы обнаруживать и исправлять любые поврежденные сектора в устройствах.
Удаление устройств из массива
Можно удалить устройство из массива, сначала пометив его как неисправное:
И уже после непосредственно удалить из массива:
Для удаления устройства навсегда (например, чтобы использовать его отдельно с этого момента): введите две команды, описанные выше, затем:
Предупреждение:
- Не вводите эту команду для линейных массивов или массивов RAID0, иначе произойдет потеря данных!
- Повторное использование удаленного диска без обнуления суперблока приведет к потере всех данных при следующей загрузке. (после того как mdadm попытается использовать его как часть массива raid).
Для того чтобы прекратить использовать массив:
Добавление нового устройства в массив
Добавление новых устройств с помощью mdadm можно выполнить в работающей системе с подключенными устройствами. Разбейте новое устройство, используя ту же схему, что и в массивах, как описано выше.
Соберите массив RAID, если он еще не собран:
Добавьте новое устройство в массив:
Это не должно занять много времени для mdadm.
И наблюдать за прогрессом добавления:
Проверить, что устройство было добавлено к массиву, можно командой:
Это связано с тем, что приведенные выше команды добавят новый диск как «запасной», но RAID0 не имеет резервных дисков. Если вы хотите добавить устройство в массив RAID0, вам нужно «увеличить» его и «добавить» командой, показанной ниже:
Увеличение размера тома RAID
Если в массиве RAID установлены диски большего размера или размер раздела увеличен, есть возможность увеличить том RAID, чтобы заполнить больший доступный объем. Этот процесс можно начать, следуя приведенным командам для замены дисков. После того, как том RAID был перестроен на большие диски, его необходимо «увеличить», чтобы заполнить пространство.
Затем, возможно, потребуется изменить размер разделов на томе RAID / dev / md0. Наконец нужно изменить файловую систему в разделе. Если разбиение делали с помощью gparted, это произойдет автоматически. Если использовали другие инструменты, размонтируйте, а затем измените размер файловой системы вручную.
Изменение ограничения скорости синхронизации
Синхронизация может занять некоторое время. Если машина не нужна для других задач, ограничение скорости можно увеличить.
Проверьте текущий предел скорости:
Увеличим имеющиеся лимиты:
Используя sysctl, также можно изменить нижний и верхний предел скорости./etc/sysctl.d/md_speedX
Если mdadm скомпилирован как модуль md_mod, эти настройки доступны только после его загрузки. Если настройки должны быть загружены через /etc/sysctl.d, модуль md_mod может быть загружен заранее через /etc/modules-load.d.
Мониторинг
Простой однострочник, который распечатывает состояние устройств RAID:
Наблюдение за mdstat
Если желаете, с использованием Tmux:
Отслеживание ввода-вывода с iotop
Пакет iotop отображает статистику ввода / вывода для процессов. Используйте эту команду для просмотра ввода-вывода для потоков RAID.
Отслеживание ввода-вывода с iostat
Утилита iostat из пакета sysstat отображает статистику ввода / вывода для устройств и разделов.
Рассылка по событиям
Для этого требуется почтовый сервер smtp (sendmail) или хотя бы сервер пересылки электронной почты (ssmtp / msmtp). Возможно, самое простое решение — это использовать пакет dma, он очень маленький (устанавливает до 0,08 МБ) и не требует настройки.
Отредактируйте /etc/mdadm.conf, указав адрес электронной почты, на который будут поступать уведомления.
Примечание: При использовании dma пользователи могут просто отправлять почту непосредственно на имя пользователя на локальном хосте, а не на внешний адрес электронной почты.
Для тестирования конфигурации:
Альтернативный метод
Чтобы избежать установки почтового сервера smtp или сервера пересылки электронной почты, вы можете использовать инструмент S-nail (не забудьте настроить), уже установленный в вашей системе.
Создайте файл с именем /etc/mdadm_warning.sh:
И дайте ему разрешение на выполнение chmod + x /etc/mdadm_warning.sh.Затем добавьте это в mdadm.conf
Для тестирования и включения используйте те же операции, что и в предыдущем методе.
Отладка
Это не обязательно означает, что диск сломан. Возможно, вы просто изменили настройки APIC или ACPI в параметрах BIOS или ядра. Поменяйте их обратно, и все будет хорошо. Обычно должно помочь отключение ACPI и / или ACPI.
Запуск массивов только для чтения
Для установки параметра при загрузке добавьте md_mod.start_ro=1 к строке ядра.
Или установите его во время загрузки модуля из файла /etc/modprobe.d/ или непосредственно из /sys/:
Восстановление из сломанного или пропавшего диска в RAID
Вы можете получить вышеупомянутую ошибку, когда один из дисков ломается. В этом случае вам придется заставить raid по-прежнему включаться даже без одного диска. Введите:
Теперь вы сможете смонтировать его снова примерно так:
Теперь рейд должен снова работать и быть доступным для использования, однако без одного диска! Добавьте один раздел диска. Как только это будет сделано, вы можете добавить новый диск в рейд, выполнив:
Если вы пропишете:
Вы, вероятно, видите, что рейд сейчас активен и восстанавливается.
Вы также можете обновить свою конфигурацию.
Эталонное тестирование (Benchmarking)
Существует несколько инструментов для бенчмаркинга RAID. Самое заметное улучшение — это увеличение скорости при чтении нескольких потоков с одного тома RAID.
tiobench оценивает эти улучшения при помощи измерения полнопроточного ввода-вывода на диске.
bonnie++ проверяет модель базы данных, пробуя доступ к одному или нескольким файлам, а также создавая, читая и удаляя небольшие файлы, которые могут имитировать использование таких программ, как Squid, INN или директорию почтового ящика в формате электронной почты. Прилагаемая программа ZCAV проверяет производительность различных зон жесткого диска без записи данных.
hdparm не следует использовать для тестирования RAID, поскольку он дает противоречивые результаты.
И напоследок, несколько полезных ссылок:
Forum threads
RAID with encryption
От редакции
Если вам интересно посещать бесплатные онлайн-мероприятия по DevOps, Kubernetes, Docker, GitlabCI и др. и задавать вопросы в режиме реального времени, подключайтесь к каналу DevOps by REBRAIN.
Читайте также: