
Undo log oracle что это
Обновлено: 06.07.2024
В недавней нити обсуждения на OTN -форуме задавался вопрос:
«… так как в redo содержится как прошлая, так и текущая информация, почему нельзя использовать redo -логи для получения этой информации? Зачем нужны undo , если redo уже содержит всю необходимую информацию.»
Нить обсуждения содержит некоторые интересные ответы, но по большей части они описывают то, как работают undo и redo вместо объяснения, почему проектировщики Oracle corp . выбрали именно тот способ по реализации undo и redo , который они выбрали. Поделюсь своими мыслями о том, зачем [естественно, автор статьи – не я].
Redo предоставляет нам две качественные возможности: восстанавливаемость и эффективность. Если мы сохраняем описание каждого изменения, которое мы производим в базе данных, то у нас есть возможность, имея более раннюю копию базы данных, вновь применить весь список изменений вплоть до текущего момента. Это и есть восстанавливаемость. Если мы сделаем этот список главным в защите изменений наших данных, нам понадобится сохранять на диске совсем небольшой объём информации вместо записи на диск каждого блока данных на момент его изменения нами – это и есть приближение к эффективности. (Конечно, хотя сконцентрированность всех изменений на маленьком пространстве делает ввод-вывод более эффективным, всё же сосредоточие множества активностей на маленьком пространстве приводит к появлению дополнительного участка с повышенной конкуренцией.)
Undo (в некоторой форме) должна существовать, если нам нужна согласованность по чтению [ read - consistency ]. Никто другой не должен видеть наши изменения в данных до тех пор, пока мы не подтвердим [ commit ] их, более того, наши изменения не должны быть видны даже тем запросам, которые начали исполняться до момента подтверждения нами наших изменений – таким образом, мы должны сохранить где-нибудь более ранние версии данных. Именно здесь получаются вещи, несколько алогичные (но очень умные) с Oracle .
Взглянем более пристально на следующую redo -запись [ redo record ]. Эта запись сгенерирована в середине транзакции во время изменения значения из 42 в 43 четвёртого поля строки таблицы.
Чтобы ответить на этот вопрос, нам нужно думать «многопользовательски». (Когда пытаешься понять какую-нибудь особенность Oracle , очень легко забыть о том, что Oracle представляет собой многопользовательскую систему. И если вы проигнорируете этот факт, то вы не подумаете о том, что будет происходить с точки зрения других сессий, как забудете и о влиянии других сессий на вашу.)
Мысленный эксперимент №1. Я выполняю продолжительную транзакцию, а множество других сессий выполняют маленькие запросы и короткие транзакции. Другие сессии должны будут видеть данные такими, какими они были перед моими изменениями. Если бы они должны были посетить redo , чтобы увидеть эти данные, тогда онлайновый файл redo -лога должен был быть произвольно большим, чтобы гарантировать наличие всей необходимой информации. И эта информация требуется для журналирования изменений и вперёд, и назад для всех сессий по всем транзакциям, которые начали выполняться с момента старта моей транзакции. Что, скажем, случится, если файлы redo -лога заполнятся?
Мысленный эксперимент №2. Если моя продолжительная транзакция потерпит неудачу и её нужно будет откатить, то необходимые мне обратные изменения будут перемешаны со всеми изменениями – и прямыми, и обратными – которые сделал кто-нибудь ещё с момента старта моей транзакции. В итоге моя сессия, возможно, остановится для совершения множества случайных вводов-выводов с целью найти обратные изменения. Конечно, мы могли бы повысить эффективность этой задачи (и решить №1 лучшим образом) посредством ведения каждой отдельной транзакцией своего собственного лог-файла – но тогда мы увеличим сложность оперирования с самим файлом (открытие и закрытие файлов при каждом старте и останове транзакции), и применения для восстановления файлов redo -лога в правильном порядке.
Мысленный эксперимент №3. В настоящее время Oracle не приводит в порядок каждый изменённый блок при подтверждении транзакции. Если я подтвержу транзакцию, но не зачищу блок X , как следующая сессия, которая посещает этот блок, узнает, что моя транзакция подтверждена, и когда я её подтвердил. Если бы всё, чем мы бы пользовались, был только один redo -лог, то следующая сессия должна была бы пойти в ту точку redo -лога, которая записала изменение в блок X и идти вперёд до тех пор, пока не найдёт подтверждение записи (или выйти на конец redo -лога, или найти подходящий SCN в redo – и таким образом определить, что моя транзакция не была подтверждена или не была подтверждена «вовремя»). Но тогда каждой redo -записи для выбранной транзакции понадобился бы «указатель вперёд» на следующую redo -запись – это означает, что вы каждый раз создавали бы redo -запись, по которой вы должны вернуться назад, чтобы изменить предыдущую redo -запись. Всё это не выглядит эффективным. Таким образом, нужно иметь механизм хранения бесконечно длинного списка транзакций и их подтверждённых SCN где-нибудь в БД, такое «бесконечно» не является хорошей идеей.
И это так и происходит: вы можете выбрать какой либо процесс, для которого использование redo -лога в качестве источника для undo было бы совершенно допустимо, но когда вы начнёте рассматривать все возможные варианты многопользовательской системы со смешанной активностью, вы обнаружите, что некоторые типы активности, получается, сливаются в одну или вызывают проблемы.
Решение Oracle состоит в сохранении «полезных» обратных изменений – undo – в месте, совершенно отличном от redo . Вместо создания третьего типа структуры хранения, Oracle сделал выбор в пользу помещения их в БД с использованием обыкновенных блоков данных. Подумайте о том, как это соотносится с тем, о чём я уже упомянул.
Поскольку блоки undo – это всего лишь блоки БД, они защищены redo -логом и могут быть восстановлены точно так же, как восстанавливается БД, не вводя ничего нового с целью восстановления. Вектор «обратного» изменения, который записан в строке redo -лога, оказался в действительности вектором прямого изменения для undo -блока – мы ввели дополнительную служебную информацию в redo -лог, потому что записываем undo дважды (но именно это мы и проделываем с каждым изменением данных в любом случае – разовая запись в блок и разовая запись в redo -лог). Undo -блоки также выгодны с точки зрения LRU -механизма – если undo -блок часто используется, он остаётся в памяти, и это правильно, потому что более вероятно, что недавно сгенерированные undo являются теми undo , которые мы хотим использовать для обеспечения согласованности по чтению.
Поскольку мы храним все undo в БД, нам не нужно беспокоиться о сессиях, постоянно открывающих и закрывающих файлы. А так как сессии начинают и завершают транзакции – мы должны только выставить некий тип каталога, который регистрирует текущие активные транзакции и указывает на места в табличном пространстве undo , где транзакция вносит свои текущие undo -записи. (Это называется таблицей транзакций [ transaction table ] в заголовке undo -сегмента [ undo segment header ])
Так как мы используем блоки БД в качестве единицы хранения и раздельно храним undo для различных транзакций, то когда я записываю свой undo , моя запись получается прекрасно сгруппированной – я захватываю и заполняю один блок в каждый момент времени. Таким образом, если мне понадобится откатить свою транзакцию, чтение одного блока даст мне множество undo -записей, и я минимизирую случайное чтение операций ввода-вывода, которые мне пришлось бы делать, чтобы прочитать undo -поток в обратном направлении.
Если я начинаю очень продолжительную транзакцию во время генерации другими сессиями undo , существует степень независимости между моими undo и их undo . При поиске компромисса между «все undo помещаются в один файл» и «каждая транзакция получает свой собственный undo -файл», Oracle ввёл множество undo -сегментов – то есть, эквивалент относительно небольшого количества совместно используемых файлов. Это означает, что отдельно взятая продолжительная транзакция ограничивается одним undo -сегментом, и все другие транзакции могут продолжать повторно использовать (переписывать) любое место, оставшееся в табличном пространстве undo более эффективно. (Конечно, мы всё ещё можем столкнуться с ошибками типа «файл заполнен», но стратегия позволяет поддерживать текущую активность БД намного дольше на том же объёме дискового пространства)
Было бы невозможно объяснить все мельчайшие детали тех проблем, которые удалось обойти или минимизировать. Однако, при введении undo в БД и их использовании таким образом, как это делается в Oracle , итог получается следующим: если вы хотите знать, почему Oracle использует табличное пространство undo для согласованности по чтению вместо redo -лога, откат и вычисления точки подтверждения, подумайте обо всех сценариях, которые вам придётся исследовать, и на их основе найти способы решения, имея только redo -лог. Подобные раздумья подадут вам некие идеи дополнительных накладных расходов и дополнительного усложнения, которые придётся вам ввести, и это позволит вам понять, как табличное пространство undo позволяет делать многие вещи (относительно) проще и эффективнее.

Как вы скорее всего уже знаете, при использовании базы данных Oracle в SAP системах в качестве клиентов базы данных выступают рабочие процессы SAP инстанций ( SAP WPs ). Каждому такому процессу соответствует один рабочий процесс со стороны инстанции Oracle ( shadow process ).
Самая маленькая логическая единица, которую Oracle использует при операциях с данными - это data block . При создании базы данных его размер можно выбрать, но в SAP инсталляциях размер data block всегда 8 Кб (8 192 байт). Все данные базы данных Oracle содержатся в дата-файлах ( data files ), которые хранятся на дисковом хранилище. Однако обработка данных никогда не производится напрямую в файлах. При операциях чтения соответствующий процесс базы данных ( shadow process ) сначала копирует данные из дата-файлов в Database buffer cache (конечно, если этих данных еще нет в кэше). И только после этого передаёт данные пользователю, то есть рабочему процессу SAP. Так как все подключенные к инстанции Oracle пользователи могут совместно использовать одни и те же, скопированные из дата-файлов в Database buffer cache , данные, то данный механизм существенно ускоряет последующие операции чтения. Процесс DBW0 активируется в следующих случаях:Использование механизма отложенной записи повышает быстродействие. Во-первых, во многих случаях, прежде чем DBW0 скопирует блок на диск, данные в блоке могут несколько раз измениться. Во-вторых, повышается эффективность операций ввода-вывода, так как DBW0 часто выполняет запись сразу нескольких блоков параллельно.
Почти всегда можно руководствоваться правилом: чем больше данный кэш, тем быстрее работает база данных. Вспомните мой старый пост про это.
Но основанный на отложенной записи механизм должен избегать потери данных и обеспечивать консистентность базы данных, даже в случае сбоя любого компонента системы. А сбой может быть как аппаратным (например, сбой дискового хранилища), так и программным - сбой инстанции Oracle. Как я уже рассказывал здесь, транзакция базы данных - это LUW (logical unit of work) сервера базы данных. Так как LUW всегда атомарная, то изменения из LUW должны быть или выполнены полностью, или полностью отменены. Для достижения консистентности данных (и консистентности чтения данных) в рамках концепции LUW СУБД Oracle использует Redo-записи для отката или восстановления (например, после сбоя) и Undo-записи для отката неподтверждённых (uncommitted) транзакций.Redo-записи
Redo-записи содержат информацию необходимую и достаточную для того, чтобы реконструировать, восстановить или откатить, внесенные в базу данных с помощью SQL-запросов данные прежде всего в подтверждённых (commit) транзакциях.
Параллельно с изменением блоков данных в Database buffer cache , shadow процесс записывает Redo-записи в Redo log buffer . Это круговой буфер, находящийся в SGA , в который временно записываются все завершённые и незавершённые изменения данных. Фоновый процесс LGWR (log writer) периодически записывает порции записей из Redo log buffer последовательно на диск - в Online redo log file .
Oracle redo log file имеет заранее заданный фиксированный размер и не растёт динамически, как обычный файл. Поэтому, когда текущий Online redo log file заполняется, процесс LGWR закрывает файл и начинает запись в следующий. В SAP инсталляциях по умолчанию используется 4 группы Online redo log files по 2 копии файлов в каждой. Online redo log file , в который LGWR пишет в данный момент, называется CURRENT. А процедура переключения файлов называется log switch .
Так как количество Online redo log files также заранее ограничено, Oracle перезаписывает старые Redo-записи новыми, используя эти файлы по кругу.
Каждый log switch СУБД увеличивает LSN (log sequence number). С помощью LSN Oracle автоматически создаёт последовательные номера для Redo log files .
- при подтверждении (commit) любой транзакции,
- каждые 3 секунды,
- когда Redo log buffer полон на одну треть,
- когда DBW0 собирается записать изменённые блоки из Database buffer cache на диск, а некоторые соответствующие Redo-записи еще не были записаны в Online redo log files . Таким образом предотвращается попытка записи с опережением журналирования (write-ahead logging).
Этого достаточно для того, чтобы всегда иметь место для новых Redo-записей в Redo log buffer . При этом по умолчанию размер этого буфера при установке в SAP системах небольшой (1 - 8 Мб). Дополнительно когда пользователь (рабочий процесс SAP) подтверждает завершение (commit) транзакции, транзакции присваивается SCN (system change number) базы данных. Oracle записывает SCN , вместе с Redo-записями транзакции в Redo log buffer . При этом DBW0 нет необходимости записывать блоки данных в момент подтверждения (commit) транзакции. Потому что в СУБД Oracle используется журналирование с опережением записи. Undo-записи содержат информацию необходимую для отмены или отката любых изменений в блоках данных, которые были выполнены в результате неподтверждённых (uncommitted) транзакций . Oracle хранит Undo-записи в специальных Undo сегментах, которые хранятся в специальном пространстве - Undo space. При этом Undo space может быть реализовано двумя способами:
- Automatic Undo Management ( AUM ),
- Manual Undo Management.
При AUM администратор должен лишь создать специальное табличное пространство - Undo tablespace ( PSAPUNDO ) достаточного размера и настроить пару параметров Oracle. Управление Undo сегментами СУБД осуществляет сама. При ручном управлении необходимо создать и настроить некоторое количество Rollback segments , у которых необходимо тщательно рассчитать размер и параметры. Данные сегменты также располагаются в отдельном табличном пространстве ( PSAPROLL ). Про проблемы с данными сегментами у меня был отдельный пост. Начиная с Oracle 9i по умолчанию используется AUM . Таким образом Undo-записи хранят информацию для транзакций, сохраняя её в Undo space, как минимум, до завершения транзакции. Так как данные записи используются для отката транзакций, то Undo-записи могут быть перезаписаны только после того, как транзакция будет подтверждена (commit) или сброшена (rollback). Каждая база данных Oracle имеет свой контрольный файл ( control file ). Это маленький бинарный файл, необходимый как в момент старта базы данных, так и в процессе работы. Следовательно данный файл должен быть всегда доступен на запись.
Control file содержит записи, которые определяют физическую структуру и состояние базы данных. Например, в нём хранится информация о табличных пространствах, именах и положении дата-файлов и Online redo log files , а также текущий LSN . Oracle control file очень важен для работы базы данных. Поэтому несколько копий могут быть сохранены в разных местах, а СУБД обновляет их одновременно. В SAP системах по умолчанию сконфигурировано 3 копии control files .
Checkpoint
Checkpoint это момент времени, в котором файлы базы данных находятся в консистентном состоянии. Достигается это состояние тем, что в этот момент DBW0 сбрасывает все текущие изменённые блоки из Database buffer cache в дата-файлы. За инициацию события Checkpoint отвечает специальный фоновый процесс CKPT , который и даёт команду процессу DBW0 начать запись блоков. Одновременно Checkpoint обозначает специальную позицию в Redo log .Кроме этого процесс CKTP также выполняет следующие шаги:
- записывает информацию о Checkpoint в заголовок каждого дата-файла,
- записывает информацию о Checkpoint position в Online redo log file в контрольный файл Oracle ( control file ).
Теперь основываясь на всех механизмах, которые были описаны выше, разберём как происходит восстановление базы данных.
Речь пойдёт не о восстановлении из резервной копии базы данных, которую должен выполнять администратор. А речь пойдёт об автоматическом восстановлении базы данных, которое СУБД производит в момент старта. Так называемое instance recovery. Оно необходимо, если предыдущий останов базы данных был выполнен не чисто, например, с опцией IMMEDIATE или ABORT. Или произошёл сбой работы сервера базы данных по аппаратной или программной причине.
Автоматическое восстановление при старте содержит следующие важные шаги: В результате после открытия консистентная база данных содержит только те изменения, которые были подтверждены (commit) перед сбоем. Из процесса восстановления базы данных видно, что Online redo log files это одна из критически важных частей сервера Oracle. А если вспомнить, что в SAP установках Checkpoint наступает только в момент log switch , то при автоматическом восстановлении СУБД всегда нужен последний Online redo log file целиком. И если он будет потерян во время сбоя, то полное восстановление (complete recovery of database) будет невозможно. В результате чего данные будут потеряны, а база данных может оказаться в неконсистентном состоянии.Поэтому-то Online redo log files должны храниться минимум в двух копиях, каждая из которых расположена на отдельном диске. Так же в продуктивной системе база данных должна работать в ARCHIVELOG режиме. В этом режиме фоновый процесс ARC0 (archiver) копирует каждый только что записанный Online redo log file в Offline redo log file . Offline redo log file в своём имени содержит LSN . Понятно, что копирование возможно начать только после переключения ( log switch ) и необходимо закончить до повторного возвращения процесса LGWR к этому файлу. Так как в таком режиме перезапись старых Redo-записей в Online redo log files не разрешается до тех пор, пока эти записи не скопированы в Offline redo log files .
Ну и должно соблюдаться ещё одно ограничение: могут быть перезаписаны только те Redo-записи, которые расположены до позиции Checkpoint в Redo log . То есть соответствующие им изменения уже записаны в дата-файлы. Это гарант возможности автоматического восстановления инстанции в случае сбоя.
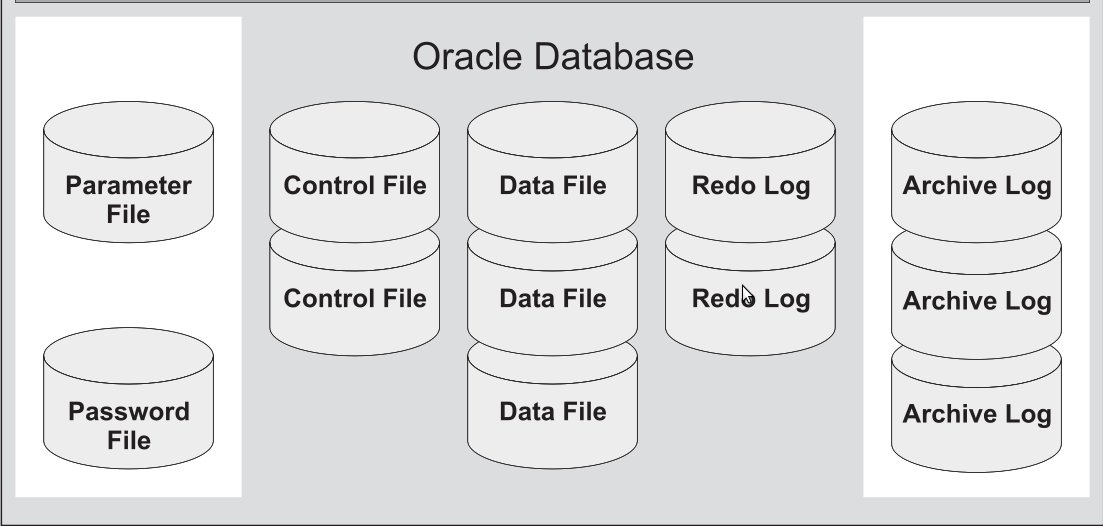
Предполагается, что вы инсталлировали базу данных, согласно документа.
Обязательные файлы:
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
Что произойдет, если не указать LOGGING/NOLOGGING при создании объектов БД?
Точнее, как будут вести себя объекты БД с опцией LOGGING/NOLOGGING и без этой опции?

LOGGING/NOLOGGING помогает управлять опцией Direct path writes (прямой путь записи в файлы данных), чтобы уменьшить генерацию REDO и UNDO. Это один из нескольких способов контролировать деликатный баланс между восстанавливаемостью данных и производительностью.
Немного общей информации по архитектуре
REDO это то, как Oracle обеспечивает прочность (durability), "D" в ACID. Когда транзакция завершается, изменения не обязательно сразу же сохраняются в файлах данных. Это ускоряет процесс и позволяет фоновым процессам справляться с некоторыми задачами. REDO - это описание изменений. Оно сохраняется быстро, на нескольких дисках, как журнал изменений. Если сервер теряет питание через доли секунды после фиксирования изменений, БД может через записи REDO убедиться, что изменения не потеряны, и востановить изменения ещё не записанные в файлы данных.
UNDO помогает обеспечить согласованность (consistency), "C" в ACID. В нем хранится описание того, как отменить изменение. Эта информация используется для отката изменений и другими процессами, которые читают таблицу и должны знать, какое значение соответствовало более раннему периоду времени.
Direct path writes не использует REDO, UNDO, кэш и некоторые другие функции, идёт непосредственная запись в файлы данных. Это быстрая, но потенциально опасная опция во многих средах, вот почему существует так много запутанных опций для управления ею. Direct path writes применяется только к INSERT , и только в сценариях, описанных ниже.
Если ничего не указывать, опция по умолчанию самая безопасная, LOGGING .
Множество способов управления Direct Path Writes
LOGGING/NOLOGGING - один из нескольких вариантов управления Direct path writes.
Посмотрите на эту таблицу из AskTom, чтобы понять, как различные опции работают вместе:
FORCE LOGING может отменить все эти настройки. Наверняка, есть другие параметры, о которых мало кто знает. И, конечно же, есть много ограничений, которые препятствуют прямому пути - триггеры, внешние ключи, кластер, индекс-организованные таблицы и т.д.
Правила в большей степени ограничены для индексов. Индекс всегда будет генерировать REDO во время DML выражений. Только DDL операторы, такие как CREATE INDEX . NOLOGGING или ALTER INDEX . REBUILD по индексу NOLOGGING не будет генерировать REDO.
Почему так много возможностей? Потому что восстанавливаемость невероятно важна, и разные стороны могут иметь разные взгляды на этот вопрос. И иногда решения одних людей должны преобладать над решениями других.
Разработчики решают на уровне запроса - "Вид на вставку". Много странных вещей может произойти с подсказкой /*+ APPEND */ , и разработчики должны тщательно выбирать, когда его использовать.
Архитекторы принимают решение на уровне объекта - "Вид на таблицу". Некоторые таблицы, независимо от того, как разработчик решит их вставить, всегда должны быть восстановлены.
*Администраторы БД" выбирают с видом на БД или табличные пространства, NOARCHIVELOG и FORCE LOGING . Может быть, организация просто не заботится о восстановлении конкретной БД, поэтому установят БД в режим NOARCHIVELOG . А может у организации есть строгое правило, что все должно быть восстанавливаемо, поэтому установят табличное пространство в режим FORCE LOGGING .
Табличное пространство UNDO используется для хранения данных UNDO. При выполнении операций DML (INSERT, UPDATE и DELETE) Oracle записывает старые данные этих операций в сегмент UNDO.
До того, как oracle9i (сегмент отката) использовался для управления данными UNDO, начиная с oracle9i, для управления данными отката можно использовать не только сегмент отката, но и табличное пространство UNDO.
При 10g кажется, что сегмент отката больше не используется для управления данными UNDO, а табличное пространство UNDO используется равномерно.
1, откат транзакции
Когда для изменения данных выполняется операция DML, данные UNDO сохраняются в сегменте UNDO, а новые данные сохраняются в сегменте данных. Если возникает проблема с операцией транзакции, необходимо откатить старую транзакцию, чтобы отменить изменение транзакции.

Пользователь А выполнил заявление UPDATE emp SET sal=9999 WHERE empno=7788 Позже выяснилось, что зарплата сотрудника 7963 должна быть изменена, а не зарплата сотрудника 7788, тогда изменение транзакции можно отменить, выполнив инструкцию ROLLBACK.
Когда команда ROLLBACK выполнена, Oracle запишет обратно данные 800 UNDO сегмента UNDO в сегмент данных.
2, прочитайте последовательность
Когда пользователь извлекает данные из базы данных, Oracle всегда позволяет пользователю видеть только данные, которые были отправлены (чтение, отправка) или данные в определенный момент времени (момент времени оператора SELECT), что может обеспечить согласованность данных.
Когда пользователь A выполняет оператор UPDATE emp SET sal=1000 WHERE empno=7788 В это время запись UNDO будет сохранена в сегменте отката, а новые данные будут сохранены в сегменте EMP, предполагается, что данные не были представлены в это время, и пользователь B выполняет SELECT sal FROM emp WHERE empno=7788 В это время пользователь B получит данные UNDO 800, и эти данные будут получены в записи UNDO.
Сеанс B (здесь мы моделируем, открывая новое окно SQL), если вы продолжаете использовать сеанс A, запрос по-прежнему 1000.
3. Восстановление транзакции
Восстановление транзакций является частью обычного восстановления, оно автоматически завершается сервером Oracle.
Если во время работы базы данных происходит сбой процедуры (например, сбой питания, сбой памяти, сбой фонового процесса и т. Д.), То при перезапуске сервера оракула фоновый процесс SMON автоматически выполняет обычное восстановление, а после выполнения обычного восстановления oracl перезапускается. Сделайте все непримененные записи. Откатите незафиксированные транзакции.
4, Flashback запрос (FlashBack Query)
Flashback-запрос используется для получения данных базы данных в определенный момент времени, он 9i Недавно добавленная функция, при условии, что текущее время - 09:00, а пользователь выполняет его в 10:00. UPDATE emp SET sal= 1000 WHERE empno=7369 Сформулируйте, измените и отправьте транзакцию (начальная зарплата сотрудника составляет 800), чтобы получить зарплату сотрудника до 10:00, пользователи могут использовать функцию запроса обратной связи.
Усовершенствование функции Oracle10g Flashback Query
Запрос Flashback Oracle 9i может предоставить представление данных только в определенный момент времени и не может сказать пользователю, что такие данные прошли через несколько транзакций и как их изменить (UPDATE, INSERT, DELETE и т. Д.), И эта информация находится в сегменте отката Да, в Oracle10g Oracle дополнительно усиливает характеристики запроса на возврат, предоставляя следующие два типа запроса на возврат:
- Flashback Versions Query
- Flashback Transaction Query
Запрос версии Flashback позволяет новому предложению VERSIONS запрашивать версию данных между двумя точками времени или SCN. Эти версии можно различить по транзакции. Запрос версии Flashback возвращает только отправленные данные, а незафиксированные данные не отображаются.
Запрос версии флэшбэка Oracle10g может получить все операции транзакции над таблицей данных, используя предложение VERSIONS и вводя в таблицу данных серию псевдостолбцов (version_starttime и т. Д.). ), VERSIONS_XID является важной основой, представляющей идентификатор транзакции разных версий.
Посредством вышеуказанного запроса, согласно version_xid, вы можете четко различать изменения, внесенные в данные различными транзакциями в разное время.
Так как этот запрос должен получить предварительную информацию от Undo, если информация в Undo будет перезаписана, приведенный выше запрос завершится ошибкой.
Восстановление данных Каштан
Пользователь обновил или случайно удалил пакет данных (при условии большого объема данных),
Вот фрагмент данных для демонстрации: первоначальная зарплата 7369 с номером работы составляет 800, а обновленная зарплата - 1000
В это время пользователь хочет восстановить, предполагая, что момент удаления - после 2016-11-13 09:00:00, затем мы находим SCN (номер изменения системы) до 9 часов.
SCN предоставляет механизм внутренних часов Oracle, который можно рассматривать как логические часы, которые необходимы для операций восстановления.
1. Получить текущий SCN
2. Извлечь данные о точке scn в таблицу emp.

Можно видеть, что данные до этого момента времени 7369 равны 800.
3. Затем вы можете выполнить операцию восстановления на основе этих данных.
С точки зрения приложения ORA-01555
1. Время выполнения запроса слишком велико. Первый - оптимизировать запрос, затем рассмотреть возможность его выполнения, когда блок данных не занят, и, наконец, рассмотреть возможность увеличения сегмента отката.
3. Consistent = y используется при выражении exp. Этот параметр предназначен главным образом для обеспечения того, чтобы все таблицы везде были согласованы в определенный момент времени во время exp, чтобы избежать таблиц с отношениями первичного и внешнего ключей из-за разных моментов времени Несоответствие разрушает целостность данных. Эту операцию рекомендуется выполнять, когда система находится в режиме ожидания.
4. Если сегмент отката не был переработан из-за отвода сегмента отката, данные в сегменте отката не могут быть найдены. Вы можете только увеличить сегмент отката, чтобы увеличить оптимальные настройки.
Отмена Oracle имеет два способа: один - использовать отмену табличного пространства, а другой - использовать сегмент отката.
Мы проходим undo_management Параметры для управления, какой метод использовать,
Если установлено значение auto, используется табличное пространство UNDO, и в это время необходимо указать табличное пространство UNDO.
Если установлено значение «Вручную», система использует сегмент отката для сохранения информации об отмене после запуска системы.
Отменить значение параметра конфигурации
- UNDO_MANAGEMENT режим управления отмены, разделенный на автоматический и ручной
- UNDO_TABLESPACE Таблица отмены, используемая в настоящее время
UNDO_RETENTION указывает, как долго данные не могут быть перезаписаны.
АВТО означает, что отмена находится в автоматическом режиме управления.
900 означает, что данные об отмене не могут быть перезаписаны в течение 900 секунд.
UNDOTBS1 - табличное пространство отмены, используемое в настоящее время
Если система не указывает undo_management, то система запускается по умолчанию в ручном режиме, даже если параметры автоматического режима установлены, эти параметры будут игнорироваться.
Использовать сегмент отката
Когда undo_management установлен в MENUAL При использовании сегмента отката системы записи об отмене записываются в сегмент SYSTEM в табличном пространстве SYSTEM.

С помощью приведенного выше утверждения мы обнаружили, что системный сегмент, используемый для отката, существует
С системным табличным пространством. По умолчанию существует только один сегмент, и он все еще относительно мал, поэтому если вы используете системный сегмент для хранения отмененных записей, это определенно повлияет на производительность базы данных. и так Oracle рекомендует использовать табличное пространство Undo для управления записями отмены.
Использовать отмену табличного пространства
Когда undo_management установлен в AUTO При использовании табличного пространства UNDO для управления сегментом отката в это время у нас будет несколько сегментов отмены, и эти сегменты будут храниться в табличном пространстве UNDO, так что производительность БД будет улучшена.

В настоящее время наша база данных имеет 58 отмененных сегментов. По умолчанию кажется 10.
В дополнение к результатам, просматриваемым через таблицу dba_segment, вы также можете использовать v r o l l s t a t с v роллстат и в Сверните два представления для просмотра информации, эти два представления будут отображать всю информацию о сегменте отката, включая сегмент системы и сегмент отмены.

Используйте следующий SQL для просмотра соотношения между простоями и без простоя в табличном пространстве отмены:

UNEXPIRED и EXPIRED - отмененные табличные пространства, которые использовались,
Среди них истек срок действия означает, что данные, срок действия которых истек, то есть данные, отличные от 15 минут (по умолчанию), были перезаписаны и могут рассматриваться как бездействующие.
Вот параметр: UNDO_RETENTION Этот параметр используется для указания максимальной продолжительности хранения записей отмены в секундах. Это динамический параметр, который можно изменить в любое время при работе экземпляра. Обычно значение по умолчанию составляет 900 секунд, что составляет 15 минут.
undo_retention указывает только срок действия данных отмены, но это не означает, что данные отмены будут сохраняться в табличном пространстве отмены в течение 15 минут. Например, когда начинается новая транзакция, если табличное пространство отмены уже заполнено, Данные новой транзакции будут автоматически перезаписывать данные отправленной транзакции, независимо от того, истек ли срок действия данных ,
Поэтому это снова относится к первому пункту: при создании табличного пространства отмены с автоматическим управлением следует также обратить внимание на размер пространства и попытаться убедиться, что в табличном пространстве отмены достаточно места для хранения.
По истечении времени, указанного в undo_retention, данные в зафиксированной транзакции будут сразу же недоступны. Они недействительны. Пока они не перезаписываются другими транзакциями, они все равно будут существовать и на них можно будет ссылаться в любое время с помощью функции возврата.
Если табличное пространство для отмены достаточно велико, а база данных не так занята, то значение параметра undo_retention не повлияет на вас, даже если вы установите его равным 1, пока нет транзакции для перезаписи данных отмены, оно будет продолжать действовать. Короче говоря, обратите внимание на размер табличного пространства отмены, чтобы убедиться, что в нем достаточно места для хранения.
Только в одном случае табличное пространство отмены может гарантировать, что данные в отмене должны быть действительными до истечения времени, указанного в undo_retention, то есть для табличного пространства отмены. Retention Guarantee После указания oracle не будет перезаписывать данные отмены в табличном пространстве отмены, срок действия которого не истек.
Запрет на отмену гарантии сохранения табличного пространства
Табличное пространство UNDO будет использоваться повторно, только когда транзакция не завершилась или гарантия сохранения включена или не может быть повторно использована в течение времени отмены удержания.
В течение времени, указанного в undo_retention, все данные действительны и после истечения срока их действия будут установлены на недействительные. Статус изменится на Истек, и эти сегменты отката будут рассматриваться как свободное пространство. Но пока данные не перезаписаны, их можно использовать.
Если пространство заполнено, данные новой транзакции будут автоматически перезаписывать данные транзакции, которые были зафиксированы, даже во время отмены удержания. Если не указано удержание
Гарантийный режим, чтобы гарантировать, что он не покрыт undo_retention.
Что касается введения принципа автоматической настройки Oracle UNDO, автоматическое управление табличным пространством, функция автоматической настройки наименьшего срока хранения информации UNDO была добавлена в более поздней версии Oracle 10gr2, больше не только на основе установки параметра UNDO_RETENTION, принцип настройки заключается в следующем :
1 Когда UNDO TABLESPACE имеет фиксированный размер, Oracle автоматически отрегулирует время хранения информации об отмене в соответствии с размером табличного пространства и историческим использованием, а также проигнорирует значение undo_retention, если не включена функция гарантии undo_retention.
2 Когда UNDO TABLESPACE равен AUM, Oracle динамически корректирует минимальное время хранения информации об отзыве на максимальное время запроса (MAXQUERYLEN) этого периода плюс 300 секунд или больше параметра UNDO_RETENTION, т.е. MAX ((MAXQUERYLEN + 300), UNDO_RENTION );
При включенной автоматической настройке фактическое минимальное время хранения информации об отзыве можно узнать, запросив V U N D O S T A T В виде инжир на из T U N E D U N D O R E T E N T I O N колонка Выиграть Получить 。 в в наиболее короткая Protect Сохранить Время между далеко далеко большой в Предполагать набор из U N D O R E T E N T I O N 。 в нет закон на U N D O T A B L E S P A C E делать фаза должен ремонт изменение из ситуация состояние , Можно к через прошлое ремонт изменение скрытый формула Женьшень число ” U N D O A U T O T U N E ” за F A L S E выключи близко от шаг мелодия отлично специальный секс 。 к на Предполагать набор Здоровье эффект задний , V Столбец TUNEDUNDORETENTION в представлении UNDOSTAT получен. Самое короткое время хранения часто намного дольше, чем установленное UNDORETENTION. Когда UNDOTABLESPACE нельзя изменить соответствующим образом, функцию автоматической настройки можно отключить для FALSE, изменив неявный параметр «UNDOAUTOTUNE». После того как вышеуказанные настройки вступят в силу, V Столбец TUNED_UNDORETENTION в представлении UNDOSTAT больше не обновляется, а минимальное время хранения информации об отмене фиксируется в значении параметра UNDO_RETENTION. Этот параметр может быть установлен динамически без перезапуска базы данных.
По умолчанию Undo_retention составляет всего 15 минут. Это значение по умолчанию, как правило, не является удовлетворительным.
Системные Требования. Общая рекомендация - изменить его на 3 часа, чтобы в случае возникновения ситуации было больше времени.
конечно, Чем больше параметр undo_retention, тем больше требуется табличное пространство для отмены , Это необходимо объединить с вашей собственной системой для установки этого параметра.
Имитация ОТМЕНА табличного пространства заполнена
Решение
Есть два метода обработки,
- Одним из них является добавление файла данных табличного пространства отмены,
- Вторым является переключение табличного пространства UNDO, в этом случае оно чаще всего используется, когда табличное пространство отмены уже очень велико.
Добавить файлы данных
Переключить UNDO табличное пространство
1. Создайте новое табличное пространство UNDOTBS2
2. Переключитесь на вновь созданное табличное пространство UNOD, операция выглядит следующим образом
3. Переведите исходное табличное пространство UNDO в автономный режим:
4. Удалите исходное табличное пространство UNDO:
Если это просто отбросить табличное пространство UNDO, будут удалены только записи в контрольном файле, и файл не будет удален физически.
Удаление табличного пространства отмены может быть выполнено только тогда, когда оно не используется. Если используется табличное пространство отмены (например, транзакция не удалась, но восстановление не было успешным), команда сброса табличного пространства завершится неудачно. Вы можете использовать содержимое при удалении табличных пространств.
Большинство случаев, когда отмена повреждена, вызваны ненормальным временем простоя. Когда об ошибке сообщают во время запуска, DB не может быть запущен.
Например: ORA-00600: внутренний код ошибки, аргументы: [4194]
Когда в журнале оповещений появляется ORA-600 + [4194], можно сделать вывод, что табличное пространство отмены повреждено. В случае отмены повреждения лучше всего использовать резервную копию для восстановления, в противном случае ее можно восстановить только некоторыми специальными методами.
Способ 1: использовать системный сегмент
Когда мы используем поврежденную табличную область отмены, мы можем сначала использовать системный сегмент для запуска БД,
После запуска заново создайте табличное пространство UNDO, для запуска используйте отмену. Действуйте следующим образом:
(1) Создайте pfile с помощью spfile, а затем измените параметры:
Как создать PFILE через SPFILE?
pfile file-Linux и другие платформы в каталоге $ ORACLE_HOME / dbs,
Oralce читает при запуске экземпляра $ORACLE_HOME/dbs Следующий файл инициализации.
(2) Используйте модифицированный pfile для перезапуска БД
(3) Удалить исходное табличное пространство и создать новое табличное пространство UNDO
(4) Закройте базу данных, измените параметры pfile, а затем создайте spfile с новым pfile и запустите базу данных в обычном режиме.
Если используется значение по умолчанию, оно может быть сокращено как:
Способ 2: пропустить поврежденный сегмент
В первом методе мы использовали системный сегмент. Из предыдущего описания мы узнали, что есть несколько отмененных сегментов, мы можем использовать журнал предупреждений, чтобы увидеть, какие сегменты используются, эти сегменты могут быть повреждены. Нам нужно только пропустить эти поврежденные сегменты, сначала запустить обычную БД, создать новое табличное пространство UNDO и переключиться.
(1) Измените pfile и добавьте параметры:
Значения этих полей можно просмотреть через журнал предупреждений. Вы также можете просмотреть его с помощью следующей команды:
(2) Запустите БД с измененным pfile
Поскольку поврежденные сегменты были пропущены, БД может нормально запускаться.
(3) Создайте новое табличное пространство UNDO и переключитесь
Читайте также: